//#0 virDomainMigrateVersion3Full // (domain=0x55555567a690, dconn=0x5555556731d0, xmlin=0x0, dname=0x0, uri=0x0, bandwidth=0, params=0x0, nparams=0, useParams=true, flags=1) // at ../src/libvirt-domain.c:3224 //#1 0x00007ffff7c6eb9b in virDomainMigrateVersion3Params // (flags=1, nparams=0, params=0x0, dconn=0x5555556731d0, domain=0x55555567a690) at ../src/libvirt-domain.c:3532 //#2 virDomainMigrate3 // (domain=domain@entry=0x55555567a690, dconn=dconn@entry=0x5555556731d0, params=<optimized out>, nparams=0, flags=flags@entry=1) // at ../src/libvirt-domain.c:4311 //#3 0x00005555555a36f1 in doMigrate (opaque=0x7fffffffd8b0) // at ../tools/virsh-domain.c:11097 //#4 0x00007ffff7b2f5b9 in virThreadHelper (data=<optimized out>) // at ../src/util/virthread.c:256 //#5 0x00007ffff7494ac3 in start_thread (arg=<optimized out>) // at ./nptl/pthread_create.c:442 //#6 0x00007ffff7526850 in clone3 () // at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
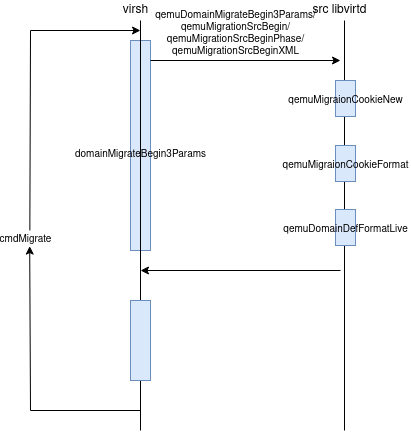
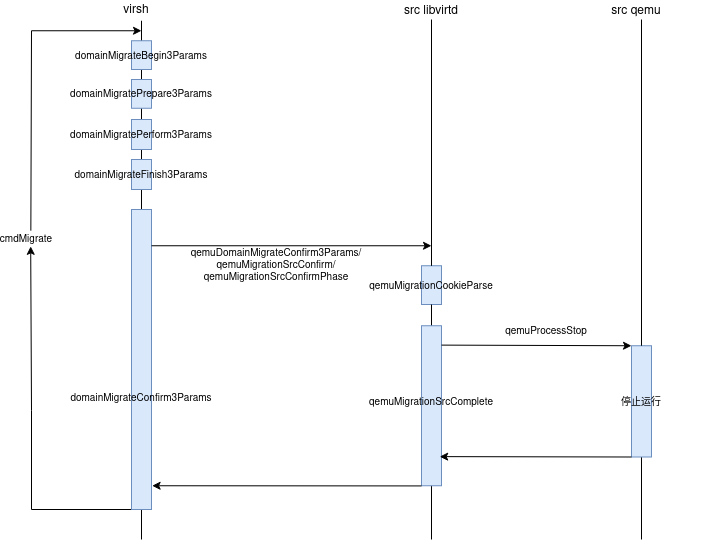
/* * Sequence v3: * * Src: Begin * - Generate XML to pass to dst * - Generate optional cookie to pass to dst * * Dst: Prepare * - Get ready to accept incoming VM * - Generate optional cookie to pass to src * * Src: Perform * - Start migration and wait for send completion * - Generate optional cookie to pass to dst * * Dst: Finish * - Wait for recv completion and check status * - Kill off VM if failed, resume if success * - Generate optional cookie to pass to src * * Src: Confirm * - Kill off VM if success, resume if failed * * If useParams is true, params and nparams contain migration parameters and * we know it's safe to call the API which supports extensible parameters. * Otherwise, we have to use xmlin, dname, uri, and bandwidth and pass them * to the old-style APIs. */ static virDomainPtr virDomainMigrateVersion3Full(virDomainPtr domain, virConnectPtr dconn, constchar *xmlin, constchar *dname, constchar *uri, unsignedlonglong bandwidth, virTypedParameterPtr params, int nparams, bool useParams, unsignedint flags) { ... VIR_DEBUG("Begin3 %p", domain->conn); ... VIR_DEBUG("Prepare3 %p flags=0x%x", dconn, destflags); ...
/* Perform the migration. The driver isn't supposed to return * until the migration is complete. The src VM should remain * running, but in paused state until the destination can * confirm migration completion. */ VIR_DEBUG("Perform3 %p uri=%s", domain->conn, uri); ...
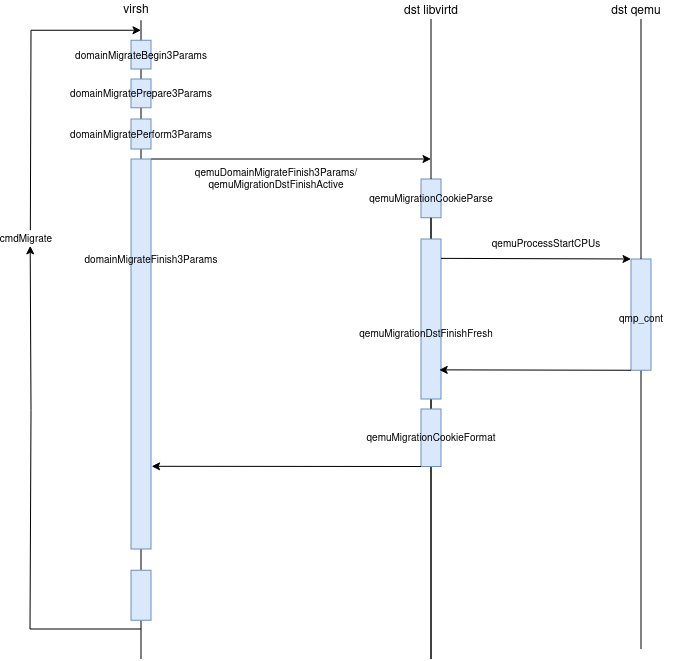
/* * The status code from the source is passed to the destination. * The dest can cleanup if the source indicated it failed to * send all migration data. Returns NULL for ddomain if * the dest was unable to complete migration. */ VIR_DEBUG("Finish3 %p ret=%d", dconn, ret); ...
/* * If cancelled, then src VM will be restarted, else it will be killed. * Don't do this if migration failed on source and thus it was already * cancelled there. */ if (notify_source) { VIR_DEBUG("Confirm3 %p ret=%d domain=%p", domain->conn, ret, domain); ... } ... }
/* This internal version appends to an existing buffer * (possibly with auto-indent), rather than flattening * to string. * Return -1 on failure. */ int virDomainDefFormatInternalSetRootName(virDomainDef *def, virDomainXMLOption *xmlopt, virBuffer *buf, constchar *rootname, unsignedint flags) { unsignedchar *uuid; char uuidstr[VIR_UUID_STRING_BUFLEN]; constchar *type = NULL; int n; size_t i; bool migratable = !!(flags & VIR_DOMAIN_DEF_FORMAT_MIGRATABLE);
if (!(type = virDomainVirtTypeToString(def->virtType))) { virReportError(VIR_ERR_INTERNAL_ERROR, _("unexpected domain type %1$d"), def->virtType); return-1; }
/* When changing this condition, beware that tests such as qemuxml*test * were optimized based on this predicate and may need to be fixed. */ if (def->id == -1) flags |= VIR_DOMAIN_DEF_FORMAT_INACTIVE;
if (virDomainCpuDefFormat(buf, def) < 0) return-1;
virDomainDefIOThreadsFormat(buf, def);
if (virDomainCputuneDefFormat(buf, def, flags) < 0) return-1;
if (virDomainNumatuneFormatXML(buf, def->numa) < 0) return-1;
virDomainResourceDefFormat(buf, def->resource);
for (i = 0; i < def->nsysinfo; i++) { if (virSysinfoFormat(buf, def->sysinfo[i]) < 0) return-1; }
if (def->os.bootloader) { virBufferEscapeString(buf, "<bootloader>%s</bootloader>\n", def->os.bootloader); virBufferEscapeString(buf, "<bootloader_args>%s</bootloader_args>\n", def->os.bootloaderArgs); }
virBufferAddLit(buf, "<os"); if (def->os.firmware && !migratable) virBufferAsprintf(buf, " firmware='%s'", virDomainOsDefFirmwareTypeToString(def->os.firmware)); virBufferAddLit(buf, ">\n"); virBufferAdjustIndent(buf, 2); virBufferAddLit(buf, "<type"); if (def->os.arch) virBufferAsprintf(buf, " arch='%s'", virArchToString(def->os.arch)); if (def->os.machine) virBufferAsprintf(buf, " machine='%s'", def->os.machine); /* * HACK: For xen driver we previously used bogus 'linux' as the * os type for paravirt, whereas capabilities declare it to * be 'xen'. So we convert to the former for backcompat */ if (def->virtType == VIR_DOMAIN_VIRT_XEN && def->os.type == VIR_DOMAIN_OSTYPE_XEN) virBufferAsprintf(buf, ">%s</type>\n", virDomainOSTypeToString(VIR_DOMAIN_OSTYPE_LINUX)); else virBufferAsprintf(buf, ">%s</type>\n", virDomainOSTypeToString(def->os.type));
if (def->os.firmwareFeatures && !migratable) { virBufferAddLit(buf, "<firmware>\n"); virBufferAdjustIndent(buf, 2);
for (i = 0; i < VIR_DOMAIN_OS_DEF_FIRMWARE_FEATURE_LAST; i++) { if (def->os.firmwareFeatures[i] == VIR_TRISTATE_BOOL_ABSENT) continue;
for (n = 0; n < def->ndisks; n++) if (virDomainDiskDefFormat(buf, def->disks[n], flags, xmlopt) < 0) return-1;
for (n = 0; n < def->ncontrollers; n++) if (virDomainControllerDefFormat(buf, def->controllers[n], flags) < 0) return-1;
for (n = 0; n < def->nleases; n++) virDomainLeaseDefFormat(buf, def->leases[n]);
for (n = 0; n < def->nfss; n++) if (virDomainFSDefFormat(buf, def->fss[n], flags) < 0) return-1;
for (n = 0; n < def->nnets; n++) if (virDomainNetDefFormat(buf, def->nets[n], xmlopt, flags) < 0) return-1;
for (n = 0; n < def->nsmartcards; n++) if (virDomainSmartcardDefFormat(buf, def->smartcards[n], flags) < 0) return-1;
for (n = 0; n < def->nserials; n++) if (virDomainChrDefFormat(buf, def->serials[n], flags) < 0) return-1;
for (n = 0; n < def->nparallels; n++) if (virDomainChrDefFormat(buf, def->parallels[n], flags) < 0) return-1;
for (n = 0; n < def->nconsoles; n++) { virDomainChrDef console; /* Back compat, ignore the console element for hvm guests * if it is type == serial */ if (def->os.type == VIR_DOMAIN_OSTYPE_HVM && (def->consoles[n]->targetType == VIR_DOMAIN_CHR_CONSOLE_TARGET_TYPE_SERIAL || def->consoles[n]->targetType == VIR_DOMAIN_CHR_CONSOLE_TARGET_TYPE_NONE) && (n < def->nserials)) { memcpy(&console, def->serials[n], sizeof(console)); console.deviceType = VIR_DOMAIN_CHR_DEVICE_TYPE_CONSOLE; console.targetType = VIR_DOMAIN_CHR_CONSOLE_TARGET_TYPE_SERIAL; } else { memcpy(&console, def->consoles[n], sizeof(console)); } if (virDomainChrDefFormat(buf, &console, flags) < 0) return-1; }
for (n = 0; n < def->nchannels; n++) if (virDomainChrDefFormat(buf, def->channels[n], flags) < 0) return-1;
for (n = 0; n < def->ninputs; n++) { if (virDomainInputDefFormat(buf, def->inputs[n], flags) < 0) return-1; }
for (n = 0; n < def->ntpms; n++) { if (virDomainTPMDefFormat(buf, def->tpms[n], flags, xmlopt) < 0) return-1; }
for (n = 0; n < def->ngraphics; n++) { if (virDomainGraphicsDefFormat(buf, def->graphics[n], flags) < 0) return-1; }
for (n = 0; n < def->nsounds; n++) { if (virDomainSoundDefFormat(buf, def->sounds[n], flags) < 0) return-1; }
for (n = 0; n < def->naudios; n++) { if (virDomainAudioDefFormat(buf, def->audios[n]) < 0) return-1; }
for (n = 0; n < def->nvideos; n++) { if (virDomainVideoDefFormat(buf, def->videos[n], flags) < 0) return-1; }
for (n = 0; n < def->nhostdevs; n++) { /* If parentnet != NONE, this is just a pointer to the * hostdev in a higher-level device (e.g. virDomainNetDef), * and will have already been formatted there. */ if (!def->hostdevs[n]->parentnet && virDomainHostdevDefFormat(buf, def->hostdevs[n], flags, xmlopt) < 0) { return-1; } }
for (n = 0; n < def->nredirdevs; n++) { if (virDomainRedirdevDefFormat(buf, def->redirdevs[n], flags) < 0) return-1; }
if (def->redirfilter) virDomainRedirFilterDefFormat(buf, def->redirfilter);
for (n = 0; n < def->nhubs; n++) { if (virDomainHubDefFormat(buf, def->hubs[n], flags) < 0) return-1; }
for (n = 0; n < def->nwatchdogs; n++) virDomainWatchdogDefFormat(buf, def->watchdogs[n], flags);
if (def->memballoon) virDomainMemballoonDefFormat(buf, def->memballoon, flags);
for (n = 0; n < def->nrngs; n++) { if (virDomainRNGDefFormat(buf, def->rngs[n], flags)) return-1; }
if (def->nvram) virDomainNVRAMDefFormat(buf, def->nvram, flags);
for (n = 0; n < def->npanics; n++) virDomainPanicDefFormat(buf, def->panics[n]);
for (n = 0; n < def->nshmems; n++) virDomainShmemDefFormat(buf, def->shmems[n], flags);
for (n = 0; n < def->nmems; n++) { if (virDomainMemoryDefFormat(buf, def->mems[n], flags) < 0) return-1; }
for (n = 0; n < def->ncryptos; n++) { virDomainCryptoDefFormat(buf, def->cryptos[n], flags); } if (def->iommu) virDomainIOMMUDefFormat(buf, def->iommu);
if (def->vsock) virDomainVsockDefFormat(buf, def->vsock);
if (def->pstore) virDomainPstoreDefFormat(buf, def->pstore, flags);
if (qemuMigrationCookieFormat(mig, driver, vm, QEMU_MIGRATION_DESTINATION, cookieout, cookieoutlen, cookieFlags) < 0) { /* We could tear down the whole guest here, but * cookie data is (so far) non-critical, so that * seems a little harsh. We'll just warn for now. */ VIR_WARN("Unable to encode migration cookie"); } ... }
/* We don't store the uuid, name, hostname, or hostuuid * values. We just compare them to local data to do some * sanity checking on migration operation */
/* Extract domain name */ if (!(name = virXPathString("string(./name[1])", ctxt))) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("missing name element in migration data")); return-1; } if (STRNEQ(name, mig->name)) { virReportError(VIR_ERR_INTERNAL_ERROR, _("Incoming cookie data had unexpected name %1$s vs %2$s"), name, mig->name); return-1; }
/* Extract domain uuid */ if (!(uuid = virXPathString("string(./uuid[1])", ctxt))) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("missing uuid element in migration data")); return-1; } virUUIDFormat(mig->uuid, localdomuuid); if (STRNEQ(uuid, localdomuuid)) { virReportError(VIR_ERR_INTERNAL_ERROR, _("Incoming cookie data had unexpected UUID %1$s vs %2$s"), uuid, localdomuuid); return-1; }
if (!(mig->remoteHostname = virXPathString("string(./hostname[1])", ctxt))) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("missing hostname element in migration data")); return-1; } /* Historically, this is the place where we checked whether remoteHostname * and localHostname are the same. But even if they were, it doesn't mean * the domain is migrating onto the same host. Rely on UUID which can tell * for sure. */
/* Check & forbid localhost migration */ if (!(hostuuid = virXPathString("string(./hostuuid[1])", ctxt))) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("missing hostuuid element in migration data")); return-1; } if (virUUIDParse(hostuuid, mig->remoteHostuuid) < 0) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("malformed hostuuid element in migration data")); return-1; } if (memcmp(mig->remoteHostuuid, mig->localHostuuid, VIR_UUID_BUFLEN) == 0) { virReportError(VIR_ERR_INTERNAL_ERROR, _("Attempt to migrate guest to the same host %1$s"), hostuuid); return-1; }
if (qemuMigrationCookieXMLParseMandatoryFeatures(ctxt, flags) < 0) return-1;
if ((virXPathNodeSet("./domain", ctxt, &nodes)) != 1) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("Too many domain elements in migration cookie")); return-1; }
if (tunnel) { if (virFDStreamOpen(st, dataFD[1]) < 0) { virReportSystemError(errno, "%s", _("cannot pass pipe for tunnelled migration")); goto error; } dataFD[1] = -1; /* 'st' owns the FD now & will close it */ }
if (qemuMigrationDstPrepareAnyBlockDirtyBitmaps(vm, mig, migParams, flags) < 0) goto error;
if (qemuMigrationParamsCheck(vm, VIR_ASYNC_JOB_MIGRATION_IN, migParams, mig->caps->supported, mig->caps->automatic) < 0) goto error;
/* Save original migration parameters */ qemuDomainSaveStatus(vm);
/* Migrations using TLS need to add the "tls-creds-x509" object and * set the migration TLS parameters */ if (flags & VIR_MIGRATE_TLS) { if (qemuMigrationParamsEnableTLS(driver, vm, true, VIR_ASYNC_JOB_MIGRATION_IN, &tlsAlias, NULL, migParams) < 0) goto error; } else { if (qemuMigrationParamsDisableTLS(vm, migParams) < 0) goto error; }
if (qemuMigrationParamsApply(vm, VIR_ASYNC_JOB_MIGRATION_IN, migParams, flags) < 0) goto error;
if (flags & VIR_MIGRATE_TLS) { if (!virQEMUCapsGet(priv->qemuCaps, QEMU_CAPS_NBD_TLS)) { virReportError(VIR_ERR_OPERATION_UNSUPPORTED, "%s", _("QEMU NBD server does not support TLS transport")); goto error; }
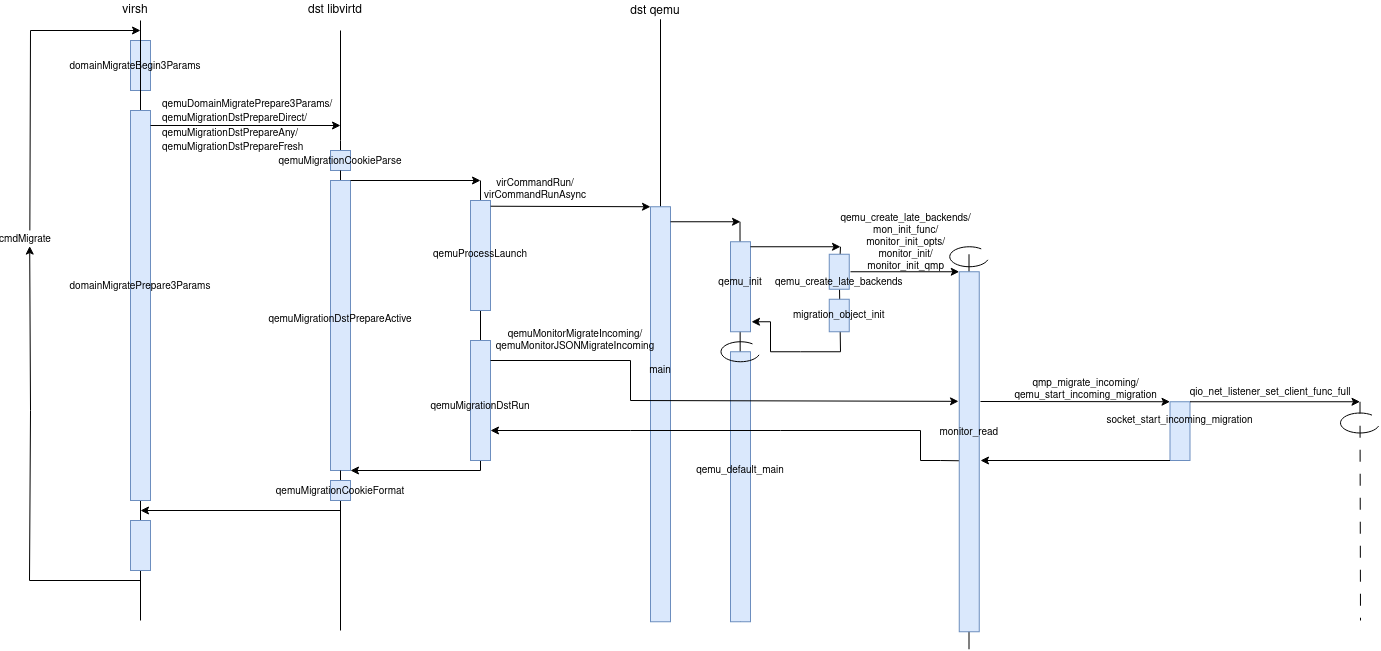
/** * qemuProcessLaunch: * * Launch a new QEMU process with stopped virtual CPUs. * * The caller is supposed to call qemuProcessStop with appropriate * flags in case of failure. * * Returns 0 on success, * -1 on error which happened before devices were labeled and thus * there is no need to restore them, * -2 on error requesting security labels to be restored. */ int qemuProcessLaunch(virConnectPtr conn, virQEMUDriver *driver, virDomainObj *vm, virDomainAsyncJob asyncJob, qemuProcessIncomingDef *incoming, virDomainMomentObj *snapshot, virNetDevVPortProfileOp vmop, unsignedint flags) { ... if (!(cmd = qemuBuildCommandLine(vm, incoming ? "defer" : NULL, snapshot, vmop, &nnicindexes, &nicindexes))) goto cleanup;
if (incoming && incoming->fd != -1) virCommandPassFD(cmd, incoming->fd, 0); ...
VIR_DEBUG("Setting up raw IO"); if (qemuProcessSetupRawIO(vm, cmd) < 0) goto cleanup;
... VIR_DEBUG("Setting up process limits");
/* In some situations, eg. VFIO passthrough, QEMU might need to lock a * significant amount of memory, so we need to set the limit accordingly */ maxMemLock = qemuDomainGetMemLockLimitBytes(vm->def);
/* For all these settings, zero indicates that the limit should * not be set explicitly and the default/inherited limit should * be applied instead */ if (maxMemLock > 0) virCommandSetMaxMemLock(cmd, maxMemLock); if (cfg->maxProcesses > 0) virCommandSetMaxProcesses(cmd, cfg->maxProcesses); if (cfg->maxFiles > 0) virCommandSetMaxFiles(cmd, cfg->maxFiles); if (cfg->schedCore == QEMU_SCHED_CORE_EMULATOR || cfg->schedCore == QEMU_SCHED_CORE_FULL) virCommandSetRunAmong(cmd, priv->schedCoreChildPID);
/* In this case, however, zero means that core dumps should be * disabled, and so we always need to set the limit explicitly */ virCommandSetMaxCoreSize(cmd, cfg->maxCore);
VIR_DEBUG("Setting up security labelling"); if (qemuSecuritySetChildProcessLabel(driver->securityManager, vm->def, false, cmd) < 0) goto cleanup;
/* wait for qemu process to show up */ if (rv == 0) { if ((rv = virPidFileReadPath(priv->pidfile, &vm->pid)) < 0) { virReportSystemError(-rv, _("Domain %1$s didn't show up"), vm->def->name); goto cleanup; } VIR_DEBUG("QEMU vm=%p name=%s running with pid=%lld", vm, vm->def->name, (longlong)vm->pid); } else { VIR_DEBUG("QEMU vm=%p name=%s failed to spawn", vm, vm->def->name); goto cleanup; }
VIR_DEBUG("Writing early domain status to disk"); if (virDomainObjSave(vm, driver->xmlopt, cfg->stateDir) < 0) goto cleanup;
VIR_DEBUG("Waiting for handshake from child"); if (virCommandHandshakeWait(cmd) < 0) { /* Read errors from child that occurred between fork and exec. */ qemuProcessReportLogError(logCtxt, _("Process exited prior to exec")); goto cleanup; }
VIR_DEBUG("Building domain mount namespace (if required)"); if (qemuDomainBuildNamespace(cfg, vm) < 0) goto cleanup;
VIR_DEBUG("Setting up domain cgroup (if required)"); if (qemuSetupCgroup(vm, nnicindexes, nicindexes) < 0) goto cleanup;
VIR_DEBUG("Setting up domain perf (if required)"); if (qemuProcessEnablePerf(vm) < 0) goto cleanup;
/* This must be done after cgroup placement to avoid resetting CPU * affinity */ if (qemuProcessInitCpuAffinity(vm) < 0) goto cleanup;
VIR_DEBUG("Setting emulator tuning/settings"); if (qemuProcessSetupEmulator(vm) < 0) goto cleanup;
VIR_DEBUG("Setting cgroup for external devices (if required)"); if (qemuSetupCgroupForExtDevices(vm, driver) < 0) goto cleanup;
VIR_DEBUG("Setting up resctrl"); if (qemuProcessResctrlCreate(driver, vm) < 0) goto cleanup;
VIR_DEBUG("Setting up managed PR daemon"); if (virDomainDefHasManagedPR(vm->def) && qemuProcessStartManagedPRDaemon(vm) < 0) goto cleanup;
VIR_DEBUG("Setting up permissions to allow post-copy migration"); if (qemuProcessAllowPostCopyMigration(vm) < 0) goto cleanup;
/* Security manager labeled all devices, therefore * if any operation from now on fails, we need to ask the caller to * restore labels. */ ret = -2;
if (incoming && incoming->fd != -1) { /* if there's an fd to migrate from, and it's a pipe, put the * proper security label on it */ structstatstdin_sb;
VIR_DEBUG("setting security label on pipe used for migration");
if (fstat(incoming->fd, &stdin_sb) < 0) { virReportSystemError(errno, _("cannot stat fd %1$d"), incoming->fd); goto cleanup; } if (S_ISFIFO(stdin_sb.st_mode) && qemuSecuritySetImageFDLabel(driver->securityManager, vm->def, incoming->fd) < 0) goto cleanup; }
VIR_DEBUG("Labelling done, completing handshake to child"); if (virCommandHandshakeNotify(cmd) < 0) goto cleanup; VIR_DEBUG("Handshake complete, child running");
if (qemuDomainObjStartWorker(vm) < 0) goto cleanup;
VIR_DEBUG("Waiting for monitor to show up"); if (qemuProcessWaitForMonitor(driver, vm, asyncJob, logCtxt) < 0) goto cleanup;
if (qemuConnectAgent(driver, vm) < 0) goto cleanup;
VIR_DEBUG("setting up hotpluggable cpus"); if (qemuDomainHasHotpluggableStartupVcpus(vm->def)) { if (qemuDomainRefreshVcpuInfo(vm, asyncJob, false) < 0) goto cleanup;
if (qemuProcessValidateHotpluggableVcpus(vm->def) < 0) goto cleanup;
if (qemuProcessSetupHotpluggableVcpus(vm, asyncJob) < 0) goto cleanup; }
VIR_DEBUG("Setting any required VM passwords"); if (qemuProcessInitPasswords(driver, vm, asyncJob) < 0) goto cleanup;
/* set default link states */ /* qemu doesn't support setting this on the command line, so * enter the monitor */ VIR_DEBUG("Setting network link states"); if (qemuProcessSetLinkStates(vm, asyncJob) < 0) goto cleanup;
if (qemuProcessSetupDiskThrottling(vm, asyncJob) < 0) goto cleanup;
/* Since CPUs were not started yet, the balloon could not return the memory * to the host and thus cur_balloon needs to be updated so that GetXMLdesc * and friends return the correct size in case they can't grab the job */ if (!incoming && !snapshot && qemuProcessRefreshBalloonState(vm, asyncJob) < 0) goto cleanup;
if (flags & VIR_QEMU_PROCESS_START_AUTODESTROY) virCloseCallbacksDomainAdd(vm, conn, qemuProcessAutoDestroy);
if (!incoming && !snapshot) { VIR_DEBUG("Setting up transient disk"); if (qemuProcessSetupDisksTransient(vm, asyncJob) < 0) goto cleanup; }
VIR_DEBUG("Setting handling of lifecycle actions"); if (qemuProcessSetupLifecycleActions(vm, asyncJob) < 0) goto cleanup;
if (qemuProcessDeleteThreadContextHelper(vm, asyncJob) < 0) goto cleanup;
/** * qemuMigrationParamsApply * @driver: qemu driver * @vm: domain object * @asyncJob: migration job * @migParams: migration parameters to send to QEMU * @apiFlags: migration flags, some of them may affect which parameters are applied * * Send parameters stored in @migParams to QEMU. If @apiFlags is non-zero, some * parameters that do not make sense for the enabled flags will be ignored. * VIR_MIGRATE_POSTCOPY_RESUME is the only flag checked currently. * * Returns 0 on success, -1 on failure. */ int qemuMigrationParamsApply(virDomainObj *vm, int asyncJob, qemuMigrationParams *migParams, unsignedint apiFlags) { bool postcopyResume = !!(apiFlags & VIR_MIGRATE_POSTCOPY_RESUME); int ret = -1;
if (qemuDomainObjEnterMonitorAsync(vm, asyncJob) < 0) return-1;
/* Changing capabilities is only allowed before migration starts, we need * to skip them when resuming post-copy migration. */ if (!postcopyResume) { if (asyncJob == VIR_ASYNC_JOB_NONE) { if (!virBitmapIsAllClear(migParams->caps)) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("Migration capabilities can only be set by a migration job")); goto cleanup; } } elseif (qemuMigrationParamsApplyCaps(vm, migParams->caps) < 0) { goto cleanup; } }
if (qemuMigrationParamsApplyValues(vm, migParams, postcopyResume) < 0) goto cleanup;
machine_opts_dict = qdict_new(); if (userconfig) { qemu_read_default_config_file(&error_fatal); }
/* second pass of option parsing */ optind = 1; for(;;) { if (optind >= argc) break; if (argv[optind][0] != '-') { loc_set_cmdline(argv, optind, 1); drive_add(IF_DEFAULT, 0, argv[optind++], HD_OPTS); } else { const QEMUOption *popt;
popt = lookup_opt(argc, argv, &optarg, &optind); if (!(popt->arch_mask & arch_type)) { error_report("Option not supported for this target"); exit(1); } switch(popt->index) { case QEMU_OPTION_cpu: /* hw initialization will check this */ cpu_option = optarg; break; case QEMU_OPTION_hda: case QEMU_OPTION_hdb: case QEMU_OPTION_hdc: case QEMU_OPTION_hdd: drive_add(IF_DEFAULT, popt->index - QEMU_OPTION_hda, optarg, HD_OPTS); break; ... default: error_report("Option not supported in this build"); exit(1); } } } /* * Clear error location left behind by the loop. * Best done right after the loop. Do not insert code here! */ loc_set_none();
/* * The trace backend must be initialized after daemonizing. * trace_init_backends() will call st_init(), which will create the * trace thread in the parent, and also register st_flush_trace_buffer() * in atexit(). This function will force the parent to wait for the * writeout thread to finish, which will not occur, and the parent * process will be left in the host. */ if (!trace_init_backends()) { exit(1); } trace_init_file();
/* * Note: uses machine properties such as kernel-irqchip, must run * after qemu_apply_machine_options. */ configure_accelerators(argv[0]); phase_advance(PHASE_ACCEL_CREATED);
/* * Beware, QOM objects created before this point miss global and * compat properties. * * Global properties get set up by qdev_prop_register_global(), * called from user_register_global_props(), and certain option * desugaring. Also in CPU feature desugaring (buried in * parse_cpu_option()), which happens below this point, but may * only target the CPU type, which can only be created after * parse_cpu_option() returned the type. * * Machine compat properties: object_set_machine_compat_props(). * Accelerator compat props: object_set_accelerator_compat_props(), * called from do_configure_accelerator(). */
machine_class = MACHINE_GET_CLASS(current_machine); if (!qtest_enabled() && machine_class->deprecation_reason) { warn_report("Machine type '%s' is deprecated: %s", machine_class->name, machine_class->deprecation_reason); }
/* * Create backends before creating migration objects, so that it can * check against compatibilities on the backend memories (e.g. postcopy * over memory-backend-file objects). */ qemu_create_late_backends(); phase_advance(PHASE_LATE_BACKENDS_CREATED);
/* * Note: creates a QOM object, must run only after global and * compat properties have been set up. */ migration_object_init();
/* parse features once if machine provides default cpu_type */ current_machine->cpu_type = machine_class_default_cpu_type(machine_class); if (cpu_option) { current_machine->cpu_type = parse_cpu_option(cpu_option); } /* NB: for machine none cpu_type could STILL be NULL here! */
//#0 qmp_dispatcher_co_wake () at ../monitor/qmp.c:359 //#1 0x0000555555ec78c4 in handle_qmp_command (opaque=0x555556f2b950, // req=0x7fffc8002570, err=0x0) at ../monitor/qmp.c:425 //#2 0x0000555555f85ce5 in json_message_process_token (lexer=0x555556f2ba18, // input=0x555556f34f90, type=JSON_RCURLY, x=47, y=0) // at ../qobject/json-streamer.c:99 //#3 0x0000555555fd4811 in json_lexer_feed_char (lexer=0x555556f2ba18, // ch=125 '}', flush=false) at ../qobject/json-lexer.c:313 //#4 0x0000555555fd4981 in json_lexer_feed (lexer=0x555556f2ba18, // buffer=0x7ffff6e8e940 "}", size=1) at ../qobject/json-lexer.c:350 //#5 0x0000555555f85ddf in json_message_parser_feed (parser=0x555556f2ba00, // buffer=0x7ffff6e8e940 "}", size=1) at ../qobject/json-streamer.c:121 //#6 0x0000555555ec7923 in monitor_qmp_read (opaque=0x555556f2b950, // buf=0x7ffff6e8e940 "}", size=1) at ../monitor/qmp.c:432 //#7 0x0000555555ebe318 in qemu_chr_be_write_impl (s=0x555557156660, // buf=0x7ffff6e8e940 "}", len=1) at ../chardev/char.c:214 //#8 0x0000555555ebe38d in qemu_chr_be_write (s=0x555557156660, // buf=0x7ffff6e8e940 "}", len=1) at ../chardev/char.c:226 //#9 0x0000555555eb9a2f in tcp_chr_read (chan=0x7fffc8000cd0, cond=G_IO_IN, // opaque=0x555557156660) at ../chardev/char-socket.c:512 //#10 0x0000555555dd6a55 in qio_channel_fd_source_dispatch ( // source=0x555557156f60, callback=0x555555eb98a7 <tcp_chr_read>, // user_data=0x555557156660) at ../io/channel-watch.c:84 //#11 0x00007ffff7da5385 in ?? () // from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#12 0x00007ffff7da75b7 in ?? () // from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#13 0x00007ffff7da801f in g_main_loop_run () // from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#14 0x0000555555e03d32 in iothread_run (opaque=0x5555570275a0) // at ../iothread.c:70 //#15 0x0000555555f93cfe in qemu_thread_start (args=0x555556f2d820) // at ../util/qemu-thread-posix.c:541 //#16 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#17 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 staticvoidhandle_qmp_command(void *opaque, QObject *req, Error *err) { MonitorQMP *mon = opaque; QDict *qdict = qobject_to(QDict, req); QMPRequest *req_obj; ... req_obj = g_new0(QMPRequest, 1); req_obj->mon = mon; req_obj->req = req; req_obj->err = err;
/* Protect qmp_requests and fetching its length. */ WITH_QEMU_LOCK_GUARD(&mon->qmp_queue_lock) { ... /* * Put the request to the end of queue so that requests will be * handled in time order. Ownership for req_obj, req, * etc. will be delivered to the handler side. */ trace_monitor_qmp_in_band_enqueue(req_obj, mon, mon->qmp_requests->length); assert(mon->qmp_requests->length < QMP_REQ_QUEUE_LEN_MAX); g_queue_push_tail(mon->qmp_requests, req_obj); }
/* Kick the dispatcher routine */ qmp_dispatcher_co_wake(); }
//#0 monitor_init_globals () at ../monitor/monitor.c:713 //#1 0x0000555555b3fcda in qemu_init_subsystems () at ../system/runstate.c:824 //#2 0x0000555555b46ca2 in qemu_init (argc=55, argv=0x7fffffffe638) // at ../system/vl.c:2786 //#3 0x0000555555db4396 in main (argc=55, argv=0x7fffffffe638) // at ../system/main.c:47 voidmonitor_init_globals(void) { ... /* * The dispatcher BH must run in the main loop thread, since we * have commands assuming that context. It would be nice to get * rid of those assumptions. */ qmp_dispatcher_co = qemu_coroutine_create(monitor_qmp_dispatcher_co, NULL); aio_co_schedule(iohandler_get_aio_context(), qmp_dispatcher_co); }
while ((req_obj = monitor_qmp_dispatcher_pop_any()) != NULL) { ... mon = req_obj->mon; ... if (qatomic_xchg(&qmp_dispatcher_co_busy, true) == true) { /* * Someone rescheduled us (probably because a new requests * came in), but we didn't actually yield. Do that now, * only to be immediately reentered and removed from the * list of scheduled coroutines. */ qemu_coroutine_yield(); }
/* Process request */ if (req_obj->req) { if (trace_event_get_state(TRACE_MONITOR_QMP_CMD_IN_BAND)) { QDict *qdict = qobject_to(QDict, req_obj->req); QObject *id = qdict ? qdict_get(qdict, "id") : NULL; GString *id_json;
assert(!(oob && qemu_in_coroutine())); assert(monitor_cur() == NULL); if (!!(cmd->options & QCO_COROUTINE) == qemu_in_coroutine()) { if (qemu_in_coroutine()) { /* * Move the coroutine from iohandler_ctx to qemu_aio_context for * executing the command handler so that it can make progress if it * involves an AIO_WAIT_WHILE(). */ aio_co_reschedule_self(qemu_get_aio_context()); }
if (qemu_in_coroutine()) { /* * Yield and reschedule so the main loop stays responsive. * * Move back to iohandler_ctx so that nested event loops for * qemu_aio_context don't start new monitor commands. */ aio_co_reschedule_self(iohandler_get_aio_context()); } } else { /* * Actual context doesn't match the one the command needs. * * Case 1: we are in coroutine context, but command does not * have QCO_COROUTINE. We need to drop out of coroutine * context for executing it. * * Case 2: we are outside coroutine context, but command has * QCO_COROUTINE. Can't actually happen, because we get here * outside coroutine context only when executing a command * out of band, and OOB commands never have QCO_COROUTINE. */ assert(!oob && qemu_in_coroutine() && !(cmd->options & QCO_COROUTINE));
QmpDispatchBH data = { .cur_mon = cur_mon, .cmd = cmd, .args = args, .ret = &ret, .errp = &err, .co = qemu_coroutine_self(), }; aio_bh_schedule_oneshot(iohandler_get_aio_context(), do_qmp_dispatch_bh, &data); qemu_coroutine_yield(); } qobject_unref(args); if (err) { /* or assert(!ret) after reviewing all handlers: */ qobject_unref(ret); goto out; }
if (cmd->options & QCO_NO_SUCCESS_RESP) { g_assert(!ret); returnNULL; } elseif (!ret) { /* * When the command's schema has no 'returns', cmd->fn() * leaves @ret null. The QMP spec calls for an empty object * then; supply it. */ ret = QOBJECT(qdict_new()); }
//对应的qapi/migration.json ## # @migrate-incoming: # # Start an incoming migration, the qemu must have been started with # -incoming defer # # @uri: The Uniform Resource Identifier identifying the source or # address to listen on # # @channels: list of migration stream channels with each stream in the # list connected to a destination interface endpoint. # # Since: 2.3 # # Notes: # # 1. It's a bad idea to use a string for the uri, but it needs to # stay compatible with -incoming and the format of the uri is # already exposed above libvirt. # # 2. QEMU must be started with -incoming defer to allow # migrate-incoming to be used. # # 3. The uri format is the same as for -incoming # # 4. For now, number of migration streams is restricted to one, # i.e. number of items in 'channels' list is just 1. # # 5. The 'uri' and 'channels' arguments are mutually exclusive; # exactly one of the two should be present. # # Example: # # -> { "execute": "migrate-incoming", # "arguments": { "uri": "tcp:0:4446" } } # <- { "return": {} } # # -> { "execute": "migrate-incoming", # "arguments": { # "channels": [ { "channel-type": "main", # "addr": { "transport": "socket", # "type": "inet", # "host": "10.12.34.9", # "port": "1050" } } ] } } # <- { "return": {} } # # -> { "execute": "migrate-incoming", # "arguments": { # "channels": [ { "channel-type": "main", # "addr": { "transport": "exec", # "args": [ "/bin/nc", "-p", "6000", # "/some/sock" ] } } ] } } # <- { "return": {} } # # -> { "execute": "migrate-incoming", # "arguments": { # "channels": [ { "channel-type": "main", # "addr": { "transport": "rdma", # "host": "10.12.34.9", # "port": "1050" } } ] } } # <- { "return": {} } ## { 'command': 'migrate-incoming', 'data': {'*uri': 'str', '*channels': [ 'MigrationChannel' ] } }
//#0 socket_start_incoming_migration (saddr=0x555557316ac8, errp=0x7fffffffe178) at ../migration/socket.c:178 //#1 0x0000555555b63ee7 in qemu_start_incoming_migration (uri=0x55555794f1e0 "tcp:[::]:49152", has_channels=false, // channels=0x0, errp=0x7fffffffe178) at ../migration/migration.c:644 //#2 0x0000555555b66a00 in qmp_migrate_incoming (uri=0x55555794f1e0 "tcp:[::]:49152", has_channels=false, channels=0x0, // errp=0x7fffffffe1d8) at ../migration/migration.c:1815 //#3 0x0000555555f343a1 in qmp_marshal_migrate_incoming (args=0x7fffc80048f0, ret=0x7ffff7294da8, errp=0x7ffff7294da0) // at qapi/qapi-commands-migration.c:523 //#4 0x0000555555f806cd in do_qmp_dispatch_bh (opaque=0x7ffff7294e40) at ../qapi/qmp-dispatch.c:128 //#5 0x0000555555fadb09 in aio_bh_call (bh=0x55555734e3a0) at ../util/async.c:171 //#6 0x0000555555fadc30 in aio_bh_poll (ctx=0x555556f2abe0) at ../util/async.c:218 //#7 0x0000555555f8e7e1 in aio_dispatch (ctx=0x555556f2abe0) at ../util/aio-posix.c:423 //#8 0x0000555555fae0c5 in aio_ctx_dispatch (source=0x555556f2abe0, callback=0x0, user_data=0x0) at ../util/async.c:360 //#9 0x00007ffff7da5385 in ?? () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#10 0x00007ffff7da7c78 in g_main_context_dispatch () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#11 0x0000555555faf750 in glib_pollfds_poll () at ../util/main-loop.c:287 //#12 0x0000555555faf7db in os_host_main_loop_wait (timeout=0) at ../util/main-loop.c:310 //#13 0x0000555555faf907 in main_loop_wait (nonblocking=0) at ../util/main-loop.c:589 //#14 0x0000555555b3fbac in qemu_main_loop () at ../system/runstate.c:783 //#15 0x0000555555db435e in qemu_default_main () at ../system/main.c:37 //#16 0x0000555555db439f in main (argc=55, argv=0x7fffffffe638) at ../system/main.c:48 voidsocket_start_incoming_migration(SocketAddress *saddr, Error **errp) { QIONetListener *listener = qio_net_listener_new(); MigrationIncomingState *mis = migration_incoming_get_current(); size_t i; int num = 1;
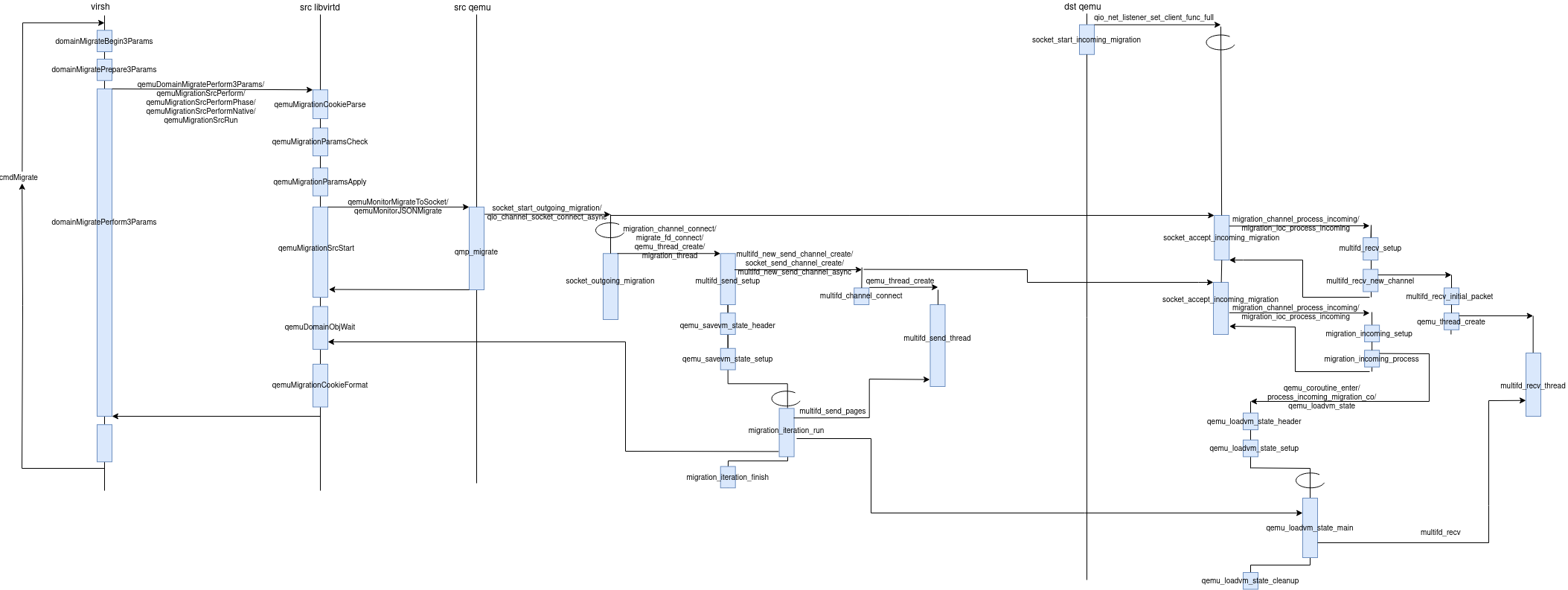
static virDomainPtr virDomainMigrateVersion3Full(virDomainPtr domain, virConnectPtr dconn, constchar *xmlin, constchar *dname, constchar *uri, unsignedlonglong bandwidth, virTypedParameterPtr params, int nparams, bool useParams, unsignedint flags) { ... /* Perform the migration. The driver isn't supposed to return * until the migration is complete. The src VM should remain * running, but in paused state until the destination can * confirm migration completion. */ VIR_DEBUG("Perform3 %p uri=%s", domain->conn, uri); VIR_FREE(cookiein); cookiein = g_steal_pointer(&cookieout); cookieinlen = cookieoutlen; cookieoutlen = 0; /* dconnuri not relevant in non-P2P modes, so left NULL here */ if (useParams) { ret = domain->conn->driver->domainMigratePerform3Params (domain, NULL, params, nparams, cookiein, cookieinlen, &cookieout, &cookieoutlen, flags | protection); } else { ret = domain->conn->driver->domainMigratePerform3 (domain, NULL, cookiein, cookieinlen, &cookieout, &cookieoutlen, NULL, uri, flags | protection, dname, bandwidth); }
/* Perform failed. Make sure Finish doesn't overwrite the error */ if (ret < 0) { virErrorPreserveLast(&orig_err); /* Perform failed so we don't need to call confirm to let source know * about the failure. */ notify_source = false; }
/* If Perform returns < 0, then we need to cancel the VM * startup on the destination */ cancelled = ret < 0 ? 1 : 0; ... }
if (qemuMigrationParamsApply(vm, VIR_ASYNC_JOB_MIGRATION_OUT, migParams, flags) < 0) goto error; ... if (qemuDomainObjEnterMonitorAsync(vm, VIR_ASYNC_JOB_MIGRATION_OUT) < 0) goto error;
if (vm->job->abortJob) { /* explicitly do this *after* we entered the monitor, * as this is a critical section so we are guaranteed * vm->job->abortJob will not change */ vm->job->current->status = VIR_DOMAIN_JOB_STATUS_CANCELED; virReportError(VIR_ERR_OPERATION_ABORTED, _("%1$s: %2$s"), virDomainAsyncJobTypeToString(vm->job->asyncJob), _("canceled by client")); goto exit_monitor; }
rc = qemuMigrationSrcStart(vm, spec, 0, &fd);
qemuDomainObjExitMonitor(vm); if (rc < 0) goto error;
/* From this point onwards we *must* call cancel to abort the * migration on source if anything goes wrong */ cancel = true; ... rc = qemuMigrationSrcWaitForCompletion(vm, VIR_ASYNC_JOB_MIGRATION_OUT, dconn, waitFlags); if (rc == -2) goto error;
/* When migration completed, QEMU will have paused the CPUs for us. * Wait for the STOP event to be processed to release the lock state. */ while (virDomainObjGetState(vm, NULL) == VIR_DOMAIN_RUNNING) { priv->signalStop = true; rc = qemuDomainObjWait(vm); priv->signalStop = false; if (rc < 0) goto error; } ... cookieFlags |= QEMU_MIGRATION_COOKIE_NETWORK | QEMU_MIGRATION_COOKIE_STATS;
/** * Returns 1 if migration completed successfully, * 0 if the domain is still being migrated, * -1 migration failed, * -2 something else failed, we need to cancel migration. */ staticint qemuMigrationAnyCompleted(virDomainObj *vm, virDomainAsyncJob asyncJob, virConnectPtr dconn, unsignedint flags) { virDomainJobData *jobData = vm->job->current; int pauseReason;
if (qemuMigrationJobCheckStatus(vm, asyncJob) < 0) goto error; ... if (jobData->status == VIR_DOMAIN_JOB_STATUS_HYPERVISOR_COMPLETED) return1; else return0; ... }
//#0 socket_outgoing_migration (task=0x555557595730, opaque=0x555557973350) at ../migration/socket.c:80 //#1 0x0000555555ddecc7 in qio_task_complete (task=0x555557595730) at ../io/task.c:197 //#2 0x0000555555dde91d in qio_task_thread_result (opaque=0x555557595730) at ../io/task.c:112 //#3 0x00007ffff7da5385 in ?? () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#4 0x00007ffff7da7c78 in g_main_context_dispatch () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#5 0x0000555555faf750 in glib_pollfds_poll () at ../util/main-loop.c:287 //#6 0x0000555555faf7db in os_host_main_loop_wait (timeout=0) at ../util/main-loop.c:310 //#7 0x0000555555faf907 in main_loop_wait (nonblocking=0) at ../util/main-loop.c:589 //#8 0x0000555555b3fbac in qemu_main_loop () at ../system/runstate.c:783 //#9 0x0000555555db435e in qemu_default_main () at ../system/main.c:37 //#10 0x0000555555db439f in main (argc=53, argv=0x7fffffffe658) at ../system/main.c:48 staticvoidsocket_outgoing_migration(QIOTask *task, gpointer opaque) { structSocketConnectData *data = opaque; QIOChannel *sioc = QIO_CHANNEL(qio_task_get_source(task)); Error *err = NULL; ... out: migration_channel_connect(data->s, sioc, data->hostname, err); object_unref(OBJECT(sioc)); }
typedefstruct { /* number of used pages */ uint32_t num; /* number of normal pages */ uint32_t normal_num; /* number of allocated pages */ uint32_t allocated; /* offset of each page */ ram_addr_t *offset; RAMBlock *block; } MultiFDPages_t;
struct { MultiFDSendParams *params; /* array of pages to sent */ MultiFDPages_t *pages; /* * Global number of generated multifd packets. * * Note that we used 'uintptr_t' because it'll naturally support atomic * operations on both 32bit / 64 bits hosts. It means on 32bit systems * multifd will overflow the packet_num easier, but that should be * fine. * * Another option is to use QEMU's Stat64 then it'll be 64 bits on all * hosts, however so far it does not support atomic fetch_add() yet. * Make it easy for now. */ uintptr_t packet_num; /* * Synchronization point past which no more channels will be * created. */ QemuSemaphore channels_created; /* send channels ready */ QemuSemaphore channels_ready; /* * Have we already run terminate threads. There is a race when it * happens that we got one error while we are exiting. * We will use atomic operations. Only valid values are 0 and 1. */ int exiting; /* multifd ops */ MultiFDMethods *ops; } *multifd_send_state;
typedefstruct { uint32_t magic; uint32_t version; uint32_t flags; /* maximum number of allocated pages */ uint32_t pages_alloc; /* non zero pages */ uint32_t normal_pages; /* size of the next packet that contains pages */ uint32_t next_packet_size; uint64_t packet_num; /* zero pages */ uint32_t zero_pages; uint32_t unused32[1]; /* Reserved for future use */ uint64_t unused64[3]; /* Reserved for future use */ char ramblock[256]; /* * This array contains the pointers to: * - normal pages (initial normal_pages entries) * - zero pages (following zero_pages entries) */ uint64_t offset[]; } __attribute__((packed)) MultiFDPacket_t;
typedefstruct { /* Fields are only written at creating/deletion time */ /* No lock required for them, they are read only */
/* channel number */ uint8_t id; /* channel thread name */ char *name; /* channel thread id */ QemuThread thread; bool thread_created; QemuThread tls_thread; bool tls_thread_created; /* communication channel */ QIOChannel *c; /* packet allocated len */ uint32_t packet_len; /* guest page size */ uint32_t page_size; /* number of pages in a full packet */ uint32_t page_count; /* multifd flags for sending ram */ int write_flags;
/* sem where to wait for more work */ QemuSemaphore sem; /* syncs main thread and channels */ QemuSemaphore sem_sync;
/* multifd flags for each packet */ uint32_t flags; /* * The sender thread has work to do if either of below boolean is set. * * @pending_job: a job is pending * @pending_sync: a sync request is pending * * For both of these fields, they're only set by the requesters, and * cleared by the multifd sender threads. */ bool pending_job; bool pending_sync; /* array of pages to sent. * The owner of 'pages' depends of 'pending_job' value: * pending_job == 0 -> migration_thread can use it. * pending_job != 0 -> multifd_channel can use it. */ MultiFDPages_t *pages;
/* thread local variables. No locking required */
/* pointer to the packet */ MultiFDPacket_t *packet; /* size of the next packet that contains pages */ uint32_t next_packet_size; /* packets sent through this channel */ uint64_t packets_sent; /* non zero pages sent through this channel */ uint64_t total_normal_pages; /* zero pages sent through this channel */ uint64_t total_zero_pages; /* buffers to send */ structiovec *iov; /* number of iovs used */ uint32_t iovs_num; /* used for compression methods */ void *compress_data; } MultiFDSendParams;
//#0 multifd_send_setup () at ../migration/multifd.c:1146 //#1 0x0000555555b6a007 in migration_thread (opaque=0x555556f34ff0) at ../migration/migration.c:3442 //#2 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) at ../util/qemu-thread-posix.c:541 //#3 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#4 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 boolmultifd_send_setup(void) { ... uint32_t page_count = MULTIFD_PACKET_SIZE / qemu_target_page_size(); ... if (!migrate_multifd()) { returntrue; }
/* We need one extra place for the packet header */ p->iov = g_new0(struct iovec, page_count + 1); } else { ... } p->name = g_strdup_printf("multifdsend_%d", i); p->page_size = qemu_target_page_size(); p->page_count = page_count; p->write_flags = 0;
if (!multifd_new_send_channel_create(p, &local_err)) { returnfalse; } }
/* * Wait until channel creation has started for all channels. The * creation can still fail, but no more channels will be created * past this point. */ for (i = 0; i < thread_count; i++) { qemu_sem_wait(&multifd_send_state->channels_created); } ... returntrue; }
staticvoid *multifd_send_thread(void *opaque) { MultiFDSendParams *p = opaque; ... int ret = 0; bool use_packets = multifd_use_packets(); ... if (use_packets) { if (multifd_send_initial_packet(p, &local_err) < 0) { ret = -1; goto out; } }
while (true) { qemu_sem_post(&multifd_send_state->channels_ready); qemu_sem_wait(&p->sem);
if (multifd_send_should_exit()) { break; }
/* * Read pending_job flag before p->pages. Pairs with the * qatomic_store_release() in multifd_send_pages(). */ if (qatomic_load_acquire(&p->pending_job)) { MultiFDPages_t *pages = p->pages;
p->iovs_num = 0; assert(pages->num);
ret = multifd_send_state->ops->send_prepare(p, &local_err); if (ret != 0) { break; }
/* * Making sure p->pages is published before saying "we're * free". Pairs with the smp_mb_acquire() in * multifd_send_pages(). */ qatomic_store_release(&p->pending_job, false); } else { /* * If not a normal job, must be a sync request. Note that * pending_sync is a standalone flag (unlike pending_job), so * it doesn't require explicit memory barriers. */ assert(qatomic_read(&p->pending_sync));
if (use_packets) { p->flags = MULTIFD_FLAG_SYNC; multifd_send_fill_packet(p); ret = qio_channel_write_all(p->c, (void *)p->packet, p->packet_len, &local_err); if (ret != 0) { break; } /* p->next_packet_size will always be zero for a SYNC packet */ stat64_add(&mig_stats.multifd_bytes, p->packet_len); p->flags = 0; }
typedefstructSaveStateEntry { QTAILQ_ENTRY(SaveStateEntry) entry; char idstr[256]; uint32_t instance_id; int alias_id; int version_id; /* version id read from the stream */ int load_version_id; int section_id; /* section id read from the stream */ int load_section_id; const SaveVMHandlers *ops; const VMStateDescription *vmsd; void *opaque; CompatEntry *compat; int is_ram; } SaveStateEntry;
structVMStateDescription { constchar *name; bool unmigratable; /* * This VMSD describes something that should be sent during setup phase * of migration. It plays similar role as save_setup() for explicitly * registered vmstate entries, so it can be seen as a way to describe * save_setup() in VMSD structures. * * Note that for now, a SaveStateEntry cannot have a VMSD and * operations (e.g., save_setup()) set at the same time. Consequently, * save_setup() and a VMSD with early_setup set to true are mutually * exclusive. For this reason, also early_setup VMSDs are migrated in a * QEMU_VM_SECTION_FULL section, while save_setup() data is migrated in * a QEMU_VM_SECTION_START section. */ bool early_setup; int version_id; int minimum_version_id; MigrationPriority priority; int (*pre_load)(void *opaque); int (*post_load)(void *opaque, int version_id); int (*pre_save)(void *opaque); int (*post_save)(void *opaque); bool (*needed)(void *opaque); bool (*dev_unplug_pending)(void *opaque);
/** * @save_state * * Saves state section on the source using the latest state format * version. * * Legacy method. Should be deprecated when all users are ported * to VMStateDescription. * * @f: QEMUFile where to send the data * @opaque: data pointer passed to register_savevm_live() */ void (*save_state)(QEMUFile *f, void *opaque);
/** * @save_prepare * * Called early, even before migration starts, and can be used to * perform early checks. * * @opaque: data pointer passed to register_savevm_live() * @errp: pointer to Error*, to store an error if it happens. * * Returns zero to indicate success and negative for error */ int (*save_prepare)(void *opaque, Error **errp);
/** * @save_setup * * Initializes the data structures on the source and transmits * first section containing information on the device * * @f: QEMUFile where to send the data * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*save_setup)(QEMUFile *f, void *opaque);
/** * @save_cleanup * * Uninitializes the data structures on the source * * @opaque: data pointer passed to register_savevm_live() */ void (*save_cleanup)(void *opaque);
/** * @save_live_complete_postcopy * * Called at the end of postcopy for all postcopyable devices. * * @f: QEMUFile where to send the data * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*save_live_complete_postcopy)(QEMUFile *f, void *opaque);
/** * @save_live_complete_precopy * * Transmits the last section for the device containing any * remaining data at the end of a precopy phase. When postcopy is * enabled, devices that support postcopy will skip this step, * where the final data will be flushed at the end of postcopy via * @save_live_complete_postcopy instead. * * @f: QEMUFile where to send the data * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*save_live_complete_precopy)(QEMUFile *f, void *opaque);
/* This runs both outside and inside the BQL. */
/** * @is_active * * Will skip a state section if not active * * @opaque: data pointer passed to register_savevm_live() * * Returns true if state section is active else false */ bool (*is_active)(void *opaque);
/** * @has_postcopy * * Checks if a device supports postcopy * * @opaque: data pointer passed to register_savevm_live() * * Returns true for postcopy support else false */ bool (*has_postcopy)(void *opaque);
/** * @is_active_iterate * * As #SaveVMHandlers.is_active(), will skip an inactive state * section in qemu_savevm_state_iterate. * * For example, it is needed for only-postcopy-states, which needs * to be handled by qemu_savevm_state_setup() and * qemu_savevm_state_pending(), but do not need iterations until * not in postcopy stage. * * @opaque: data pointer passed to register_savevm_live() * * Returns true if state section is active else false */ bool (*is_active_iterate)(void *opaque);
/* This runs outside the BQL in the migration case, and * within the lock in the savevm case. The callback had better only * use data that is local to the migration thread or protected * by other locks. */
/** * @save_live_iterate * * Should send a chunk of data until the point that stream * bandwidth limits tell it to stop. Each call generates one * section. * * @f: QEMUFile where to send the data * @opaque: data pointer passed to register_savevm_live() * * Returns 0 to indicate that there is still more data to send, * 1 that there is no more data to send and * negative to indicate an error. */ int (*save_live_iterate)(QEMUFile *f, void *opaque);
/* This runs outside the BQL! */
/** * @state_pending_estimate * * This estimates the remaining data to transfer * * Sum of @can_postcopy and @must_postcopy is the whole amount of * pending data. * * @opaque: data pointer passed to register_savevm_live() * @must_precopy: amount of data that must be migrated in precopy * or in stopped state, i.e. that must be migrated * before target start. * @can_postcopy: amount of data that can be migrated in postcopy * or in stopped state, i.e. after target start. * Some can also be migrated during precopy (RAM). * Some must be migrated after source stops * (block-dirty-bitmap) */ void (*state_pending_estimate)(void *opaque, uint64_t *must_precopy, uint64_t *can_postcopy);
/** * @state_pending_exact * * This calculates the exact remaining data to transfer * * Sum of @can_postcopy and @must_postcopy is the whole amount of * pending data. * * @opaque: data pointer passed to register_savevm_live() * @must_precopy: amount of data that must be migrated in precopy * or in stopped state, i.e. that must be migrated * before target start. * @can_postcopy: amount of data that can be migrated in postcopy * or in stopped state, i.e. after target start. * Some can also be migrated during precopy (RAM). * Some must be migrated after source stops * (block-dirty-bitmap) */ void (*state_pending_exact)(void *opaque, uint64_t *must_precopy, uint64_t *can_postcopy);
/** * @load_state * * Load sections generated by any of the save functions that * generate sections. * * Legacy method. Should be deprecated when all users are ported * to VMStateDescription. * * @f: QEMUFile where to receive the data * @opaque: data pointer passed to register_savevm_live() * @version_id: the maximum version_id supported * * Returns zero to indicate success and negative for error */ int (*load_state)(QEMUFile *f, void *opaque, int version_id);
/** * @load_setup * * Initializes the data structures on the destination. * * @f: QEMUFile where to receive the data * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*load_setup)(QEMUFile *f, void *opaque);
/** * @load_cleanup * * Uninitializes the data structures on the destination. * * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*load_cleanup)(void *opaque);
/** * @resume_prepare * * Called when postcopy migration wants to resume from failure * * @s: Current migration state * @opaque: data pointer passed to register_savevm_live() * * Returns zero to indicate success and negative for error */ int (*resume_prepare)(MigrationState *s, void *opaque);
/** * @switchover_ack_needed * * Checks if switchover ack should be used. Called only on * destination. * * @opaque: data pointer passed to register_savevm_live() * * Returns true if switchover ack should be used and false * otherwise */ bool (*switchover_ack_needed)(void *opaque); } SaveVMHandlers;
/* * ??? Mirrors the previous value of qemu_host_page_size, * but is this really what was intended for the migration? */ max_hg_page_size = MAX(qemu_real_host_page_size(), TARGET_PAGE_SIZE);
intmultifd_send_sync_main(void) { int i; bool flush_zero_copy;
if (!migrate_multifd()) { return0; } if (multifd_send_state->pages->num) { if (!multifd_send_pages()) { error_report("%s: multifd_send_pages fail", __func__); return-1; } } ... for (i = 0; i < migrate_multifd_channels(); i++) { MultiFDSendParams *p = &multifd_send_state->params[i];
if (multifd_send_should_exit()) { return-1; }
trace_multifd_send_sync_main_signal(p->id);
/* * We should be the only user so far, so not possible to be set by * others concurrently. */ assert(qatomic_read(&p->pending_sync) == false); qatomic_set(&p->pending_sync, true); qemu_sem_post(&p->sem); } for (i = 0; i < migrate_multifd_channels(); i++) { MultiFDSendParams *p = &multifd_send_state->params[i];
/* * Try to detect any kind of failures, and see whether we * should stop the migration now. */ thr_error = migration_detect_error(s); if (thr_error == MIG_THR_ERR_FATAL) { /* Stop migration */ break; } elseif (thr_error == MIG_THR_ERR_RECOVERED) { /* * Just recovered from a e.g. network failure, reset all * the local variables. This is important to avoid * breaking transferred_bytes and bandwidth calculation */ update_iteration_initial_status(s); }
trace_savevm_state_iterate(); QTAILQ_FOREACH(se, &savevm_state.handlers, entry) { if (!se->ops || !se->ops->save_live_iterate) { continue; } if (se->ops->is_active && !se->ops->is_active(se->opaque)) { continue; } if (se->ops->is_active_iterate && !se->ops->is_active_iterate(se->opaque)) { continue; } /* * In the postcopy phase, any device that doesn't know how to * do postcopy should have saved it's state in the _complete * call that's already run, it might get confused if we call * iterate afterwards. */ if (postcopy && !(se->ops->has_postcopy && se->ops->has_postcopy(se->opaque))) { continue; } if (migration_rate_exceeded(f)) { return0; } trace_savevm_section_start(se->idstr, se->section_id);
save_section_header(f, se, QEMU_VM_SECTION_PART);
ret = se->ops->save_live_iterate(f, se->opaque); trace_savevm_section_end(se->idstr, se->section_id, ret); save_section_footer(f, se);
if (ret < 0) { error_report("failed to save SaveStateEntry with id(name): " "%d(%s): %d", se->section_id, se->idstr, ret); qemu_file_set_error(f, ret); return ret; } elseif (!ret) { all_finished = false; } } return all_finished; }
if (migrate_postcopy_ram()) { /* We can do postcopy, and all the data is postcopiable */ *can_postcopy += remaining_size; } else { *must_precopy += remaining_size; } }
//#0 kvm_physical_sync_dirty_bitmap (kml=0x555556f3c100, section=0x7fffcf5fd8e0) // at ../accel/kvm/kvm-all.c:832 //#1 0x0000555555da419e in kvm_log_sync (listener=0x555556f3c100, // section=0x7fffcf5fd8e0) at ../accel/kvm/kvm-all.c:1591 //#2 0x0000555555d42b54 in memory_region_sync_dirty_bitmap (mr=0x0, // last_stage=false) at ../system/memory.c:2295 //#3 0x0000555555d44c85 in memory_global_dirty_log_sync (last_stage=false) // at ../system/memory.c:2901 //#4 0x0000555555d5913f in migration_bitmap_sync (rs=0x7fffb80043e0, // last_stage=false) at ../migration/ram.c:1063 //#5 0x0000555555d59385 in migration_bitmap_sync_precopy (rs=0x7fffb80043e0, // last_stage=false) at ../migration/ram.c:1111 //#6 0x0000555555d5c86c in ram_init_bitmaps (rs=0x7fffb80043e0) // at ../migration/ram.c:2864 //#7 0x0000555555d5c915 in ram_init_all (rsp=0x555556ea4c40 <ram_state>) // at ../migration/ram.c:2887 //#8 0x0000555555d5cf34 in ram_save_setup (f=0x55555714d4d0, // opaque=0x555556ea4c40 <ram_state>) at ../migration/ram.c:3082 //#9 0x0000555555b81e25 in qemu_savevm_state_setup (f=0x55555714d4d0) // at ../migration/savevm.c:1346 //#10 0x0000555555b6a0d7 in migration_thread (opaque=0x555556f34ff0) // at ../migration/migration.c:3477 //#11 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) // at ../util/qemu-thread-posix.c:541 //#12 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#13 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 voidmemory_global_dirty_log_sync(bool last_stage) { memory_region_sync_dirty_bitmap(NULL, last_stage); } staticvoidmemory_region_sync_dirty_bitmap(MemoryRegion *mr, bool last_stage) { MemoryListener *listener; AddressSpace *as; FlatView *view; FlatRange *fr;
/* If the same address space has multiple log_sync listeners, we * visit that address space's FlatView multiple times. But because * log_sync listeners are rare, it's still cheaper than walking each * address space once. */ QTAILQ_FOREACH(listener, &memory_listeners, link) { if (listener->log_sync) { as = listener->address_space; view = address_space_get_flatview(as); FOR_EACH_FLAT_RANGE(fr, view) { if (fr->dirty_log_mask && (!mr || fr->mr == mr)) { MemoryRegionSection mrs = section_from_flat_range(fr, view); listener->log_sync(listener, &mrs); } } flatview_unref(view); trace_memory_region_sync_dirty(mr ? mr->name : "(all)", listener->name, 0); } ... } } staticvoidkvm_log_sync(MemoryListener *listener, MemoryRegionSection *section) { KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
size = kvm_align_section(section, &start_addr); while (size) { slot_size = MIN(kvm_max_slot_size, size); mem = kvm_lookup_matching_slot(kml, start_addr, slot_size); if (!mem) { /* We don't have a slot if we want to trap every access. */ return; } if (kvm_slot_get_dirty_log(s, mem)) { kvm_slot_sync_dirty_pages(mem); } start_addr += slot_size; size -= slot_size; } }
//#0 cpu_physical_memory_sync_dirty_bitmap (rb=0x555556f2b4c0, start=0, // length=536870912) // at /home/hawk/Desktop/mqemu/qemu/include/exec/ram_addr.h:480 //#1 0x0000555555d58bea in ramblock_sync_dirty_bitmap (rs=0x7fffc4000c80, // rb=0x555556f2b4c0) at ../migration/ram.c:918 //#2 0x0000555555d591b0 in migration_bitmap_sync (rs=0x7fffc4000c80, // last_stage=false) at ../migration/ram.c:1068 //#3 0x0000555555d59385 in migration_bitmap_sync_precopy (rs=0x7fffc4000c80, // last_stage=false) at ../migration/ram.c:1111 //#4 0x0000555555d5c86c in ram_init_bitmaps (rs=0x7fffc4000c80) // at ../migration/ram.c:2864 //#5 0x0000555555d5c915 in ram_init_all (rsp=0x555556ea4c40 <ram_state>) // at ../migration/ram.c:2887 //#6 0x0000555555d5cf34 in ram_save_setup (f=0x55555714d4d0, // opaque=0x555556ea4c40 <ram_state>) at ../migration/ram.c:3082 //#7 0x0000555555b81e25 in qemu_savevm_state_setup (f=0x55555714d4d0) // at ../migration/savevm.c:1346 //#8 0x0000555555b6a0d7 in migration_thread (opaque=0x555556f34ff0) // at ../migration/migration.c:3477 //#9 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) // at ../util/qemu-thread-posix.c:541 //#10 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#11 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 staticvoidramblock_sync_dirty_bitmap(RAMState *rs, RAMBlock *rb) { uint64_t new_dirty_pages = cpu_physical_memory_sync_dirty_bitmap(rb, 0, rb->used_length);
staticintram_save_iterate(QEMUFile *f, void *opaque) { RAMState **temp = opaque; RAMState *rs = *temp; int ret = 0; int i; int64_t t0; int done = 0; ... /* * We'll take this lock a little bit long, but it's okay for two reasons. * Firstly, the only possible other thread to take it is who calls * qemu_guest_free_page_hint(), which should be rare; secondly, see * MAX_WAIT (if curious, further see commit 4508bd9ed8053ce) below, which * guarantees that we'll at least released it in a regular basis. */ WITH_QEMU_LOCK_GUARD(&rs->bitmap_mutex) { WITH_RCU_READ_LOCK_GUARD() { ... t0 = qemu_clock_get_ns(QEMU_CLOCK_REALTIME); i = 0; while ((ret = migration_rate_exceeded(f)) == 0 || postcopy_has_request(rs)) { int pages;
if (qemu_file_get_error(f)) { break; }
pages = ram_find_and_save_block(rs); /* no more pages to sent */ if (pages == 0) { done = 1; break; }
if (pages < 0) { qemu_file_set_error(f, pages); break; }
rs->target_page_count += pages; ... /* * we want to check in the 1st loop, just in case it was the 1st * time and we had to sync the dirty bitmap. * qemu_clock_get_ns() is a bit expensive, so we only check each * some iterations */ if ((i & 63) == 0) { uint64_t t1 = (qemu_clock_get_ns(QEMU_CLOCK_REALTIME) - t0) / 1000000; if (t1 > MAX_WAIT) { trace_ram_save_iterate_big_wait(t1, i); break; } } i++; } } } ...
out: if (ret >= 0 && migration_is_setup_or_active()) { if (migrate_multifd() && migrate_multifd_flush_after_each_section() && !migrate_mapped_ram()) { ret = multifd_send_sync_main(); if (ret < 0) { return ret; } }
qemu_put_be64(f, RAM_SAVE_FLAG_EOS); ram_transferred_add(8); ret = qemu_fflush(f); } if (ret < 0) { return ret; }
return done; }
staticintram_find_and_save_block(RAMState *rs) { PageSearchStatus *pss = &rs->pss[RAM_CHANNEL_PRECOPY]; int pages = 0; ... /* * Always keep last_seen_block/last_page valid during this procedure, * because find_dirty_block() relies on these values (e.g., we compare * last_seen_block with pss.block to see whether we searched all the * ramblocks) to detect the completion of migration. Having NULL value * of last_seen_block can conditionally cause below loop to run forever. */ if (!rs->last_seen_block) { rs->last_seen_block = QLIST_FIRST_RCU(&ram_list.blocks); rs->last_page = 0; }
//#0 find_dirty_block (rs=0x7fffb80043e0, pss=0x7fffb80043e0) at ../migration/ram.c:1349 //#1 0x0000555555d5b7ab in ram_find_and_save_block (rs=0x7fffb80043e0) at ../migration/ram.c:2353 //#2 0x0000555555d5d4d1 in ram_save_iterate (f=0x55555714d4d0, opaque=0x555556ea4c40 <ram_state>) at ../migration/ram.c:3240 //#3 0x0000555555b82133 in qemu_savevm_state_iterate (f=0x55555714d4d0, postcopy=false) at ../migration/savevm.c:1430 //#4 0x0000555555b69ada in migration_iteration_run (s=0x555556f34ff0) at ../migration/migration.c:3252 //#5 0x0000555555b6a141 in migration_thread (opaque=0x555556f34ff0) at ../migration/migration.c:3489 //#6 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) at ../util/qemu-thread-posix.c:541 //#7 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#8 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 staticintfind_dirty_block(RAMState *rs, PageSearchStatus *pss) { /* Update pss->page for the next dirty bit in ramblock */ pss_find_next_dirty(pss);
if (pss->complete_round && pss->block == rs->last_seen_block && pss->page >= rs->last_page) { /* * We've been once around the RAM and haven't found anything. * Give up. */ return PAGE_ALL_CLEAN; } if (!offset_in_ramblock(pss->block, ((ram_addr_t)pss->page) << TARGET_PAGE_BITS)) { /* Didn't find anything in this RAM Block */ pss->page = 0; pss->block = QLIST_NEXT_RCU(pss->block, next); if (!pss->block) { ... /* Hit the end of the list */ pss->block = QLIST_FIRST_RCU(&ram_list.blocks); /* Flag that we've looped */ pss->complete_round = true; ... } /* Didn't find anything this time, but try again on the new block */ return PAGE_TRY_AGAIN; } else { /* We've found something */ return PAGE_DIRTY_FOUND; } }
//#0 ram_save_multifd_page (block=0x555556f2b4c0, offset=0) at ../migration/ram.c:1288 //#1 0x0000555555d5b22e in ram_save_target_page_multifd (rs=0x7fffb80043e0, pss=0x7fffb80043e0) at ../migration/ram.c:2123 //#2 0x0000555555d5b60d in ram_save_host_page (rs=0x7fffb80043e0, pss=0x7fffb80043e0) at ../migration/ram.c:2281 //#3 0x0000555555d5b7e1 in ram_find_and_save_block (rs=0x7fffb80043e0) at ../migration/ram.c:2365 //#4 0x0000555555d5d4d1 in ram_save_iterate (f=0x55555714d4d0, opaque=0x555556ea4c40 <ram_state>) at ../migration/ram.c:3240 //#5 0x0000555555b82133 in qemu_savevm_state_iterate (f=0x55555714d4d0, postcopy=false) at ../migration/savevm.c:1430 //#6 0x0000555555b69ada in migration_iteration_run (s=0x555556f34ff0) at ../migration/migration.c:3252 //#7 0x0000555555b6a141 in migration_thread (opaque=0x555556f34ff0) at ../migration/migration.c:3489 //#8 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) at ../util/qemu-thread-posix.c:541 //#9 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#10 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 staticintram_save_multifd_page(RAMBlock *block, ram_addr_t offset) { if (!multifd_queue_page(block, offset)) { return-1; }
staticvoidmigration_completion(MigrationState *s) { int ret = 0; int current_active_state = s->state; Error *local_err = NULL;
... ret = migration_completion_precopy(s, ¤t_active_state); ... return; }
staticintmigration_completion_precopy(MigrationState *s, int *current_active_state) { int ret; ret = migration_stop_vm(s, RUN_STATE_FINISH_MIGRATE); if (ret < 0) { goto out_unlock; } ... ret = qemu_savevm_state_complete_precopy(s->to_dst_file, false, s->block_inactive); ... out_unlock: ... return ret; }
//#0 qemu_savevm_state_complete_precopy (f=0x55555714d4d0, iterable_only=false, inactivate_disks=true) at ../migration/savevm.c:1606 //#1 0x0000555555b68a9a in migration_completion_precopy (s=0x555556f34ff0, current_active_state=0x7fffcf5fda78) at ../migration/migration.c:2749 //#2 0x0000555555b68c61 in migration_completion (s=0x555556f34ff0) at ../migration/migration.c:2813 //#3 0x0000555555b69a3f in migration_iteration_run (s=0x555556f34ff0) at ../migration/migration.c:3237 //#4 0x0000555555b6a141 in migration_thread (opaque=0x555556f34ff0) at ../migration/migration.c:3489 //#5 0x0000555555f93cfe in qemu_thread_start (args=0x555557ab8510) at ../util/qemu-thread-posix.c:541 //#6 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#7 0x00007ffff7c637b8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 intqemu_savevm_state_complete_precopy(QEMUFile *f, bool iterable_only, bool inactivate_disks) { int ret; Error *local_err = NULL; bool in_postcopy = migration_in_postcopy();
if (precopy_notify(PRECOPY_NOTIFY_COMPLETE, &local_err)) { error_report_err(local_err); }
trace_savevm_state_complete_precopy();
cpu_synchronize_all_states();
if (!in_postcopy || iterable_only) { ret = qemu_savevm_state_complete_precopy_iterable(f, in_postcopy); if (ret) { return ret; } }
if (iterable_only) { goto flush; }
ret = qemu_savevm_state_complete_precopy_non_iterable(f, in_postcopy, inactivate_disks); if (ret) { return ret; }
//#0 migration_ioc_process_incoming (ioc=0x555557972b60, errp=0x7fffffffe298) at ../migration/migration.c:898 //#1 0x0000555555b57799 in migration_channel_process_incoming (ioc=0x555557972b60) at ../migration/channel.c:45 //#2 0x0000555555b86f2d in socket_accept_incoming_migration (listener=0x55555790a7b0, cioc=0x555557972b60, opaque=0x0) at ../migration/socket.c:150 //#3 0x0000555555ddd2d5 in qio_net_listener_channel_func (ioc=0x5555572ee1a0, condition=G_IO_IN, opaque=0x55555790a7b0) at ../io/net-listener.c:54 //#4 0x0000555555dd6a55 in qio_channel_fd_source_dispatch (source=0x55555718a0a0, callback=0x555555ddd255 <qio_net_listener_channel_func>, user_data=0x55555790a7b0) at ../io/channel-watch.c:84 //#5 0x00007ffff7da5385 in ?? () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#6 0x00007ffff7da7c78 in g_main_context_dispatch () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#7 0x0000555555faf750 in glib_pollfds_poll () at ../util/main-loop.c:287 //#8 0x0000555555faf7db in os_host_main_loop_wait (timeout=713438000) at ../util/main-loop.c:310 //#9 0x0000555555faf907 in main_loop_wait (nonblocking=0) at ../util/main-loop.c:589 //#10 0x0000555555b3fbac in qemu_main_loop () at ../system/runstate.c:783 //#11 0x0000555555db435e in qemu_default_main () at ../system/main.c:37 //#12 0x0000555555db439f in main (argc=55, argv=0x7fffffffe638) at ../system/main.c:48 voidmigration_ioc_process_incoming(QIOChannel *ioc, Error **errp) { MigrationIncomingState *mis = migration_incoming_get_current(); Error *local_err = NULL; QEMUFile *f; bool default_channel = true; uint32_t channel_magic = 0; int ret = 0;
if (migrate_multifd() && !migrate_mapped_ram() && !migrate_postcopy_ram() && qio_channel_has_feature(ioc, QIO_CHANNEL_FEATURE_READ_MSG_PEEK)) { /* * With multiple channels, it is possible that we receive channels * out of order on destination side, causing incorrect mapping of * source channels on destination side. Check channel MAGIC to * decide type of channel. Please note this is best effort, postcopy * preempt channel does not send any magic number so avoid it for * postcopy live migration. Also tls live migration already does * tls handshake while initializing main channel so with tls this * issue is not possible. */ ret = migration_channel_read_peek(ioc, (void *)&channel_magic, sizeof(channel_magic), errp);
if (default_channel) { f = qemu_file_new_input(ioc); migration_incoming_setup(f); } else { ... if (migrate_multifd()) { multifd_recv_new_channel(ioc, &local_err); } ... }
if (migration_should_start_incoming(default_channel)) { /* If it's a recovery, we're done */ if (postcopy_try_recover()) { return; } migration_incoming_process(); } }
struct { MultiFDRecvParams *params; MultiFDRecvData *data; /* number of created threads */ int count; /* * This is always posted by the recv threads, the migration thread * uses it to wait for recv threads to finish assigned tasks. */ QemuSemaphore sem_sync; /* global number of generated multifd packets */ uint64_t packet_num; int exiting; /* multifd ops */ MultiFDMethods *ops; } *multifd_recv_state;
error_setg(errp, "multifd: received uuid '%s' and expected " "uuid '%s' for channel %hhd", msg_uuid, uuid, msg.id); g_free(uuid); g_free(msg_uuid); return-1; }
if (msg.id > migrate_multifd_channels()) { error_setg(errp, "multifd: received channel id %u is greater than " "number of channels %u", msg.id, migrate_multifd_channels()); return-1; }
//#0 multifd_recv_setup (errp=0x7fffffffe298) at ../migration/multifd.c:1562 //#1 0x0000555555b64696 in migration_ioc_process_incoming (ioc=0x555557972b60, errp=0x7fffffffe298) at ../migration/migration.c:931 //#2 0x0000555555b57799 in migration_channel_process_incoming (ioc=0x555557972b60) at ../migration/channel.c:45 //#3 0x0000555555b86f2d in socket_accept_incoming_migration (listener=0x55555790a7b0, cioc=0x555557972b60, opaque=0x0) at ../migration/socket.c:150 //#4 0x0000555555ddd2d5 in qio_net_listener_channel_func (ioc=0x5555572ee1a0, condition=G_IO_IN, opaque=0x55555790a7b0) at ../io/net-listener.c:54 //#5 0x0000555555dd6a55 in qio_channel_fd_source_dispatch (source=0x55555718a0a0, callback=0x555555ddd255 <qio_net_listener_channel_func>, user_data=0x55555790a7b0) at ../io/channel-watch.c:84 //#6 0x00007ffff7da5385 in ?? () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#7 0x00007ffff7da7c78 in g_main_context_dispatch () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#8 0x0000555555faf750 in glib_pollfds_poll () at ../util/main-loop.c:287 //#9 0x0000555555faf7db in os_host_main_loop_wait (timeout=705145000) at ../util/main-loop.c:310 //#10 0x0000555555faf907 in main_loop_wait (nonblocking=0) at ../util/main-loop.c:589 //#11 0x0000555555b3fbac in qemu_main_loop () at ../system/runstate.c:783 //#12 0x0000555555db435e in qemu_default_main () at ../system/main.c:37 //#13 0x0000555555db439f in main (argc=55, argv=0x7fffffffe638) at ../system/main.c:48 intmultifd_recv_setup(Error **errp) { ... /* * Return successfully if multiFD recv state is already initialised * or multiFD is not enabled. */ if (multifd_recv_state || !migrate_multifd()) { return0; }
/* * Returns true when we want to start a new incoming migration process, * false otherwise. */ staticboolmigration_should_start_incoming(bool main_channel) { /* Multifd doesn't start unless all channels are established */ if (migrate_multifd()) { return migration_has_all_channels(); } ... }
/** * @migration_has_all_channels: We have received all channels that we need * * Returns true when we have got connections to all the channels that * we need for migration. */ boolmigration_has_all_channels(void) { MigrationIncomingState *mis = migration_incoming_get_current();
if (!mis->from_src_file) { returnfalse; }
if (migrate_multifd()) { return multifd_recv_all_channels_created(); } ... }
//#0 migration_incoming_process () at ../migration/migration.c:826 //#1 0x0000555555b51dd7 in migration_ioc_process_incoming (ioc=0x555557a922a0, errp=0x7fffffffe2b0) // at ../migration/migration.c:959 //#2 0x0000555555b455b9 in migration_channel_process_incoming (ioc=0x555557a922a0) at ../migration/channel.c:45 //#3 0x0000555555b73229 in socket_accept_incoming_migration (listener=0x5555578d57b0, cioc=0x555557a922a0, opaque=0x0) // at ../migration/socket.c:150 //#4 0x0000555555dbaea1 in qio_net_listener_channel_func (ioc=0x5555572b91a0, condition=G_IO_IN, opaque=0x5555578d57b0) // at ../io/net-listener.c:54 //#5 0x0000555555db4a8b in qio_channel_fd_source_dispatch (source=0x5555571550a0, // callback=0x555555dbae1d <qio_net_listener_channel_func>, user_data=0x5555578d57b0) at ../io/channel-watch.c:84 //#6 0x00007ffff7da5385 in ?? () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#7 0x00007ffff7da7c78 in g_main_context_dispatch () from target:/lib/x86_64-linux-gnu/libglib-2.0.so.0 //#8 0x0000555555f7d9b6 in glib_pollfds_poll () at ../util/main-loop.c:287 //#9 0x0000555555f7da44 in os_host_main_loop_wait (timeout=59822371073000) at ../util/main-loop.c:310 //#10 0x0000555555f7db64 in main_loop_wait (nonblocking=0) at ../util/main-loop.c:589 //#11 0x0000555555b2e067 in qemu_main_loop () at ../system/runstate.c:783 //#12 0x0000555555d92c24 in qemu_default_main () at ../system/main.c:37 //#13 0x0000555555d92c61 in main (argc=55, argv=0x7fffffffe638) at ../system/main.c:48 voidmigration_incoming_process(void) { Coroutine *co = qemu_coroutine_create(process_incoming_migration_co, NULL); qemu_coroutine_enter(co); }
//#0 qemu_loadvm_state (f=0x5555571184d0) at ../migration/savevm.c:2928 //#1 0x0000555555b51893 in process_incoming_migration_co (opaque=0x0) // at ../migration/migration.c:755 //#2 0x0000555555f8041f in coroutine_trampoline (i0=1470332912, i1=21845) // at ../util/coroutine-ucontext.c:175 //#3 0x00007ffff7bab890 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#4 0x00007fffffffdde0 in ?? () //#5 0x0000000000000000 in ?? () intqemu_loadvm_state(QEMUFile *f) { ... ret = qemu_loadvm_state_header(f); if (ret) { return ret; }
if (qemu_loadvm_state_setup(f) != 0) { return -EINVAL; } ... cpu_synchronize_all_pre_loadvm(); ... ret = qemu_loadvm_state_main(f, mis); ... qemu_loadvm_state_cleanup(); cpu_synchronize_all_post_init();
//#0 qemu_loadvm_state_header (f=0x5555571184d0) at ../migration/savevm.c:2690 //#1 0x0000555555b71559 in qemu_loadvm_state (f=0x5555571184d0) // at ../migration/savevm.c:2937 //#2 0x0000555555b51893 in process_incoming_migration_co (opaque=0x0) // at ../migration/migration.c:755 //#3 0x0000555555f8041f in coroutine_trampoline (i0=1470332912, i1=21845) // at ../util/coroutine-ucontext.c:175 //#4 0x00007ffff7bab890 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#5 0x00007fffffffdde0 in ?? () //#6 0x0000000000000000 in ?? () staticintqemu_loadvm_state_header(QEMUFile *f) { unsignedint v; int ret;
v = qemu_get_be32(f); if (v != QEMU_VM_FILE_MAGIC) { error_report("Not a migration stream"); return -EINVAL; }
v = qemu_get_be32(f); if (v == QEMU_VM_FILE_VERSION_COMPAT) { error_report("SaveVM v2 format is obsolete and don't work anymore"); return -ENOTSUP; } if (v != QEMU_VM_FILE_VERSION) { error_report("Unsupported migration stream version"); return -ENOTSUP; } ... return0; }
//#0 ram_load_setup (f=0x5555571184d0, opaque=0x555556e6fc40 <ram_state>) // at ../migration/ram.c:3700 //#1 0x0000555555b70fad in qemu_loadvm_state_setup (f=0x5555571184d0) // at ../migration/savevm.c:2758 //#2 0x0000555555b71576 in qemu_loadvm_state (f=0x5555571184d0) // at ../migration/savevm.c:2942 //#3 0x0000555555b51893 in process_incoming_migration_co (opaque=0x0) // at ../migration/migration.c:755 //#4 0x0000555555f8041f in coroutine_trampoline (i0=1470332912, i1=21845) // at ../util/coroutine-ucontext.c:175 //#5 0x00007ffff7bab890 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#6 0x00007fffffffdde0 in ?? () //#7 0x0000000000000000 in ?? () staticintram_load_setup(QEMUFile *f, void *opaque) { xbzrle_load_setup(); ramblock_recv_map_init();
intqemu_loadvm_state_main(QEMUFile *f, MigrationIncomingState *mis) { uint8_t section_type; int ret = 0;
retry: while (true) { section_type = qemu_get_byte(f);
ret = qemu_file_get_error_obj_any(f, mis->postcopy_qemufile_dst, NULL); if (ret) { break; }
trace_qemu_loadvm_state_section(section_type); switch (section_type) { case QEMU_VM_SECTION_START: case QEMU_VM_SECTION_FULL: ret = qemu_loadvm_section_start_full(f, mis, section_type); if (ret < 0) { goto out; } break; case QEMU_VM_SECTION_PART: case QEMU_VM_SECTION_END: ret = qemu_loadvm_section_part_end(f, mis, section_type); if (ret < 0) { goto out; } break; case QEMU_VM_COMMAND: ret = loadvm_process_command(f); trace_qemu_loadvm_state_section_command(ret); if ((ret < 0) || (ret == LOADVM_QUIT)) { goto out; } break; case QEMU_VM_EOF: /* This is the end of migration */ goto out; default: error_report("Unknown savevm section type %d", section_type); ret = -EINVAL; goto out; } } ... return ret; }
//#0 save_section_header (f=0x5555571184d0, se=0x555556f00c80, // section_type=1 '\001') at ../migration/savevm.c:985 //#1 0x0000555555b6e295 in qemu_savevm_state_setup (f=0x5555571184d0) // at ../migration/savevm.c:1344 //#2 0x0000555555b57373 in migration_thread (opaque=0x555556effff0) // at ../migration/migration.c:3477 //#3 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) // at ../util/qemu-thread-posix.c:541 //#4 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#5 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 voidqemu_savevm_state_setup(QEMUFile *f) { ... QTAILQ_FOREACH(se, &savevm_state.handlers, entry) { ... save_section_header(f, se, QEMU_VM_SECTION_START);
ret = se->ops->save_setup(f, se->opaque); ... } ... }
//#0 save_section_header (f=0x5555571184d0, se=0x555556efe790, // section_type=4 '\004') at ../migration/savevm.c:985 //#1 0x0000555555b6d5e9 in vmstate_save (f=0x5555571184d0, se=0x555556efe790, // vmdesc=0x7fffc4004280) at ../migration/savevm.c:1027 //#2 0x0000555555b6eb43 in qemu_savevm_state_complete_precopy_non_iterable ( // f=0x5555571184d0, in_postcopy=false, inactivate_disks=true) // at ../migration/savevm.c:1555 //#3 0x0000555555b6ede1 in qemu_savevm_state_complete_precopy ( // f=0x5555571184d0, iterable_only=false, inactivate_disks=true) // at ../migration/savevm.c:1630 //#4 0x0000555555b55db7 in migration_completion_precopy (s=0x555556effff0, // current_active_state=0x7fffcf5fda98) at ../migration/migration.c:2749 //#5 0x0000555555b55f40 in migration_completion (s=0x555556effff0) // at ../migration/migration.c:2813 //#6 0x0000555555b56d01 in migration_iteration_run (s=0x555556effff0) // at ../migration/migration.c:3237 //#7 0x0000555555b573dd in migration_thread (opaque=0x555556effff0) // at ../migration/migration.c:3489 //#8 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) // at ../util/qemu-thread-posix.c:541 //#9 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#10 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 intqemu_savevm_state_complete_precopy_non_iterable(QEMUFile *f, bool in_postcopy, bool inactivate_disks) { QTAILQ_FOREACH(se, &savevm_state.handlers, entry) { ... ret = vmstate_save(f, se, vmdesc); ... } ... }
staticintvmstate_save(QEMUFile *f, SaveStateEntry *se, JSONWriter *vmdesc) { ... save_section_header(f, se, QEMU_VM_SECTION_FULL); ... if (!se->vmsd) { vmstate_save_old_style(f, se, vmdesc); } else { ret = vmstate_save_state_with_err(f, se->vmsd, se->opaque, vmdesc, &local_err); ... } ... }
//#0 qemu_loadvm_section_start_full (f=0x5555571184d0, mis=0x555556f00750, // type=1 '\001') at ../migration/savevm.c:2559 //#1 0x0000555555b71414 in qemu_loadvm_state_main (f=0x5555571184d0, // mis=0x555556f00750) at ../migration/savevm.c:2869 //#2 0x0000555555b715b1 in qemu_loadvm_state (f=0x5555571184d0) // at ../migration/savevm.c:2952 //#3 0x0000555555b51893 in process_incoming_migration_co (opaque=0x0) // at ../migration/migration.c:755 //#4 0x0000555555f8041f in coroutine_trampoline (i0=1470332912, i1=21845) // at ../util/coroutine-ucontext.c:175 //#5 0x00007ffff7bab890 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#6 0x00007fffffffdde0 in ?? () //#7 0x0000000000000000 in ?? () staticint qemu_loadvm_section_start_full(QEMUFile *f, MigrationIncomingState *mis, uint8_t type) { ... /* Read section start */ section_id = qemu_get_be32(f); if (!qemu_get_counted_string(f, idstr)) { ... } ... instance_id = qemu_get_be32(f); version_id = qemu_get_be32(f); ...
/* Find savevm section */ se = find_se(idstr, instance_id); if (se == NULL) { error_report("Unknown savevm section or instance '%s' %"PRIu32". " "Make sure that your current VM setup matches your " "saved VM setup, including any hotplugged devices", idstr, instance_id); return -EINVAL; }
/* Validate version */ if (version_id > se->version_id) { error_report("savevm: unsupported version %d for '%s' v%d", version_id, idstr, se->version_id); return -EINVAL; } se->load_version_id = version_id; se->load_section_id = section_id; ... ret = vmstate_load(f, se); ... return0; }
//#0 save_section_header (f=0x5555571184d0, se=0x555556f00c80, // section_type=2 '\002') at ../migration/savevm.c:985 //#1 0x0000555555b6e5a5 in qemu_savevm_state_iterate (f=0x5555571184d0, // postcopy=false) at ../migration/savevm.c:1428 //#2 0x0000555555b56d9c in migration_iteration_run (s=0x555556effff0) // at ../migration/migration.c:3252 //#3 0x0000555555b573dd in migration_thread (opaque=0x555556effff0) // at ../migration/migration.c:3489 //#4 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) // at ../util/qemu-thread-posix.c:541 //#5 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#6 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 intqemu_savevm_state_iterate(QEMUFile *f, bool postcopy) { ... QTAILQ_FOREACH(se, &savevm_state.handlers, entry) { save_section_header(f, se, QEMU_VM_SECTION_PART);
ret = se->ops->save_live_iterate(f, se->opaque); ... } ... }
//#0 save_section_header (f=0x5555571184d0, se=0x555556f00c80, // section_type=3 '\003') at ../migration/savevm.c:985 //#1 0x0000555555b6e99c in qemu_savevm_state_complete_precopy_iterable ( // f=0x5555571184d0, in_postcopy=false) at ../migration/savevm.c:1517 //#2 0x0000555555b6edb7 in qemu_savevm_state_complete_precopy ( // f=0x5555571184d0, iterable_only=false, inactivate_disks=true) // at ../migration/savevm.c:1620 //#3 0x0000555555b55db7 in migration_completion_precopy (s=0x555556effff0, // current_active_state=0x7fffcf5fda98) at ../migration/migration.c:2749 //#4 0x0000555555b55f40 in migration_completion (s=0x555556effff0) // at ../migration/migration.c:2813 //#5 0x0000555555b56d01 in migration_iteration_run (s=0x555556effff0) // at ../migration/migration.c:3237 //#6 0x0000555555b573dd in migration_thread (opaque=0x555556effff0) // at ../migration/migration.c:3489 //#7 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) // at ../util/qemu-thread-posix.c:541 //#8 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#9 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 static intqemu_savevm_state_complete_precopy_iterable(QEMUFile *f, bool in_postcopy) { ... QTAILQ_FOREACH(se, &savevm_state.handlers, entry) { save_section_header(f, se, QEMU_VM_SECTION_END);
ret = se->ops->save_live_complete_precopy(f, se->opaque); ... } ... }
ret = se->ops->save_live_iterate(f, se->opaque); ... } ... }
//#0 ram_save_iterate (f=0x5555571184d0, opaque=0x555556e6fc40 <ram_state>) // at ../migration/ram.c:3194 //#1 0x0000555555b6e5cb in qemu_savevm_state_iterate (f=0x5555571184d0, // postcopy=false) at ../migration/savevm.c:1430 //#2 0x0000555555b56d9c in migration_iteration_run (s=0x555556effff0) // at ../migration/migration.c:3252 //#3 0x0000555555b573dd in migration_thread (opaque=0x555556effff0) // at ../migration/migration.c:3489 //#4 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) // at ../util/qemu-thread-posix.c:541 //#5 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#6 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 staticintram_save_iterate(QEMUFile *f, void *opaque) { ... /* * We'll take this lock a little bit long, but it's okay for two reasons. * Firstly, the only possible other thread to take it is who calls * qemu_guest_free_page_hint(), which should be rare; secondly, see * MAX_WAIT (if curious, further see commit 4508bd9ed8053ce) below, which * guarantees that we'll at least released it in a regular basis. */ WITH_QEMU_LOCK_GUARD(&rs->bitmap_mutex) { WITH_RCU_READ_LOCK_GUARD() { while ((ret = migration_rate_exceeded(f)) == 0 || postcopy_has_request(rs)) { ... pages = ram_find_and_save_block(rs); ... } } }
staticintmigration_completion_precopy(MigrationState *s, int *current_active_state) { if (!migrate_mode_is_cpr(s)) { ret = migration_stop_vm(s, RUN_STATE_FINISH_MIGRATE); ... } ... ret = qemu_savevm_state_complete_precopy(s->to_dst_file, false, s->block_inactive); ... return ret; }
intqemu_savevm_state_complete_precopy(QEMUFile *f, bool iterable_only, bool inactivate_disks) { ... ret = qemu_savevm_state_complete_precopy_non_iterable(f, in_postcopy, inactivate_disks); if (ret) { return ret; }
flush: return qemu_fflush(f); }
//#0 qemu_put_byte (f=0x5555576c0700, v=21845) at ../migration/qemu-file.c:560 //#1 0x0000555555b6ec76 in qemu_savevm_state_complete_precopy_non_iterable (f=0x5555571184d0, in_postcopy=false, // inactivate_disks=true) at ../migration/savevm.c:1582 //#2 0x0000555555b6ede1 in qemu_savevm_state_complete_precopy (f=0x5555571184d0, iterable_only=false, inactivate_disks=true) // at ../migration/savevm.c:1630 //#3 0x0000555555b55db7 in migration_completion_precopy (s=0x555556effff0, current_active_state=0x7fffcf5fda98) // at ../migration/migration.c:2749 //#4 0x0000555555b55f40 in migration_completion (s=0x555556effff0) at ../migration/migration.c:2813 //#5 0x0000555555b56d01 in migration_iteration_run (s=0x555556effff0) at ../migration/migration.c:3237 //#6 0x0000555555b573dd in migration_thread (opaque=0x555556effff0) at ../migration/migration.c:3489 //#7 0x0000555555f63f51 in qemu_thread_start (args=0x555557a83510) at ../util/qemu-thread-posix.c:541 //#8 0x00007ffff7be5b7b in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 //#9 0x00007ffff7c637f8 in ?? () from target:/lib/x86_64-linux-gnu/libc.so.6 intqemu_savevm_state_complete_precopy_non_iterable(QEMUFile *f, bool in_postcopy, bool inactivate_disks) { ... if (!in_postcopy) { /* Postcopy stream will still be going */ qemu_put_byte(f, QEMU_VM_EOF); } ... return0; }
intqemu_loadvm_state_main(QEMUFile *f, MigrationIncomingState *mis) { retry: while (true) { section_type = qemu_get_byte(f); ... switch (section_type) { ... case QEMU_VM_EOF: /* This is the end of migration */ goto out; ... } }
static virDomainPtr virDomainMigrateVersion3Full(virDomainPtr domain, virConnectPtr dconn, constchar *xmlin, constchar *dname, constchar *uri, unsignedlonglong bandwidth, virTypedParameterPtr params, int nparams, bool useParams, unsignedint flags) { ... /* If Perform returns < 0, then we need to cancel the VM * startup on the destination */ cancelled = ret < 0 ? 1 : 0;
finish: /* * The status code from the source is passed to the destination. * The dest can cleanup if the source indicated it failed to * send all migration data. Returns NULL for ddomain if * the dest was unable to complete migration. */ VIR_DEBUG("Finish3 %p ret=%d", dconn, ret); VIR_FREE(cookiein); cookiein = g_steal_pointer(&cookieout); cookieinlen = cookieoutlen; cookieoutlen = 0; if (useParams) { if (virTypedParamsGetString(params, nparams, VIR_MIGRATE_PARAM_DEST_NAME, NULL) <= 0 && virTypedParamsReplaceString(¶ms, &nparams, VIR_MIGRATE_PARAM_DEST_NAME, domain->name) < 0) { ddomain = NULL; } else { ddomain = dconn->driver->domainMigrateFinish3Params (dconn, params, nparams, cookiein, cookieinlen, &cookieout, &cookieoutlen, destflags, cancelled); } } else { dname = dname ? dname : domain->name; ddomain = dconn->driver->domainMigrateFinish3 (dconn, dname, cookiein, cookieinlen, &cookieout, &cookieoutlen, NULL, uri, destflags, cancelled); }
if (cancelled) { if (ddomain) { VIR_ERROR(_("finish step ignored that migration was cancelled")); } else { /* If Finish reported a useful error, use it instead of the * original "migration unexpectedly failed" error. * * This is ugly but we can't do better with the APIs we have. We * only replace the error if Finish was called with cancelled == 1 * and reported a real error (old libvirt would report an error * from RPC instead of MIGRATE_FINISH_OK), which only happens when * the domain died on destination. To further reduce a possibility * of false positives we also check that Perform returned * VIR_ERR_OPERATION_FAILED. */ if (orig_err && orig_err->domain == VIR_FROM_QEMU && orig_err->code == VIR_ERR_OPERATION_FAILED) { virErrorPtr err = virGetLastError(); if (err && err->domain == VIR_FROM_QEMU && err->code != VIR_ERR_MIGRATE_FINISH_OK) { g_clear_pointer(&orig_err, virFreeError); } } } } ... }
//#0 qemuMigrationDstFinishActive // (cookie_flags=60, driver=0x55caa06c0930, dconn=0x7fce80000c80, vm=0x7fce6407a820, cookiein=0x7fce8c0019c0 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>13d91ed2-8dc5-4c18-b3af-9e54aec2c1f1</uuid>\n <hostname>src</hostname>\n <hostuuid>43b3e83d-912b-48b6-b7e7-e0bd07f7f86d</hostuuid>\n <statistics>\n"..., cookieinlen=1141, cookieout=0x7fce9a38c970, cookieoutlen=0x7fce9a38c964, flags=131073, retcode=0, v3proto=true, timeReceived=1780186934878, finishJob=<synthetic pointer>) at ../src/qemu/qemu_migration.c:6851 //#1 qemuMigrationDstFinish // (driver=driver@entry=0x55caa06c0930, dconn=dconn@entry=0x7fce80000c80, vm=<optimized out>, cookiein=cookiein@entry=0x7fce8c0019c0 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>13d91ed2-8dc5-4c18-b3af-9e54aec2c1f1</uuid>\n <hostname>src</hostname>\n <hostuuid>43b3e83d-912b-48b6-b7e7-e0bd07f7f86d</hostuuid>\n <statistics>\n"..., cookieinlen=cookieinlen@entry=1141, cookieout=cookieout@entry=0x7fce9a38c970, cookieoutlen=0x7fce9a38c964, flags=131073, retcode=0, v3proto=true) at ../src/qemu/qemu_migration.c:7010 //#2 0x00007fce982474b7 in qemuDomainMigrateFinish3Params // (dconn=0x7fce80000c80, params=0x7fce8c001e40, nparams=3, cookiein=0x7fce8c0019c0 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>13d91ed2-8dc5-4c18-b3af-9e54aec2c1f1</uuid>\n <hostname>src</hostname>\n <hostuuid>43b3e83d-912b-48b6-b7e7-e0bd07f7f86d</hostuuid>\n <statistics>\n"..., cookieinlen=1141, cookieout=0x7fce9a38c970, cookieoutlen=0x7fce9a38c964, flags=131073, cancelled=0) at ../src/qemu/qemu_driver.c:11395 //#3 0x00007fce9d9de695 in virDomainMigrateFinish3Params // (dconn=dconn@entry=0x7fce80000c80, params=0x7fce8c001e40, nparams=3, cookiein=0x7fce8c0019c0 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>13d91ed2-8dc5-4c18-b3af-9e54aec2c1f1</uuid>\n <hostname>src</hostname>\n <hostuuid>43b3e83d-912b-48b6-b7e7-e0bd07f7f86d</hostuuid>\n <statistics>\n"..., cookieinlen=1141, cookieout=cookieout@entry=0x7fce9a38c970, cookieoutlen=0x7fce9a38c964, flags=131073, cancelled=0) at ../src/libvirt-domain.c:5485 //#4 0x000055ca9505c88f in remoteDispatchDomainMigrateFinish3Params // (server=0x55caa06afbf0, msg=0x55caa06ad1a0, client=<optimized out>, rerr=0x7fce9a38ca30, args=0x55caa06ad140, ret=0x7fce8c0013f0) at ../src/remote/remote_daemon_dispatch.c:5806 //#5 remoteDispatchDomainMigrateFinish3ParamsHelper (server=0x55caa06afbf0, client=<optimized out>, msg=0x55caa06ad1a0, rerr=0x7fce9a38ca30, args=0x55caa06ad140, ret=0x7fce8c0013f0) // at src/remote/remote_daemon_dispatch_stubs.h:8656 //#6 0x00007fce9d95b88e in virNetServerProgramDispatchCall (prog=0x55caa06b0430, server=0x55caa06afbf0, client=0x7fce70000d80, msg=0x55caa06ad1a0) at ../src/rpc/virnetserverprogram.c:423 //#7 virNetServerProgramDispatch (prog=0x55caa06b0430, server=server@entry=0x55caa06afbf0, client=client@entry=0x7fce70000d80, msg=msg@entry=0x55caa06ad1a0) // at ../src/rpc/virnetserverprogram.c:299 //#8 0x00007fce9d960e22 in virNetServerProcessMsg (srv=srv@entry=0x55caa06afbf0, client=0x7fce70000d80, prog=<optimized out>, msg=0x55caa06ad1a0) at ../src/rpc/virnetserver.c:135 //#9 0x00007fce9d96115d in virNetServerHandleJob (jobOpaque=0x7fce780a64f0, opaque=0x55caa06afbf0) at ../src/rpc/virnetserver.c:155 //#10 0x00007fce9d8a88bd in virThreadPoolWorker (opaque=<optimized out>) at ../src/util/virthreadpool.c:164 //#11 0x00007fce9d8a7f44 in virThreadHelper (data=<optimized out>) at ../src/util/virthread.c:256 //#12 0x00007fce9d201b7b in ??? () at /lib/x86_64-linux-gnu/libc.so.6 //#13 0x00007fce9d27f7f8 in ??? () at /lib/x86_64-linux-gnu/libc.so.6 static virDomainPtr qemuMigrationDstFinishActive(virQEMUDriver *driver, virConnectPtr dconn, virDomainObj *vm, int cookie_flags, constchar *cookiein, int cookieinlen, char **cookieout, int *cookieoutlen, unsignedint flags, int retcode, bool v3proto, unsignedlonglong timeReceived, bool *finishJob) { ... if (!(mig = qemuMigrationCookieParse(driver, vm, vm->def, priv->origname, priv->qemuCaps, cookiein, cookieinlen, cookie_flags))) goto error;
if (retcode != 0) { /* Check for a possible error on the monitor in case Finish was called * earlier than monitor EOF handler got a chance to process the error */ qemuDomainCheckMonitor(vm, VIR_ASYNC_JOB_MIGRATION_IN); goto error; } ... rc = qemuMigrationDstFinishFresh(driver, vm, mig, flags, v3proto, timeReceived, &doKill, &inPostCopy); ... if (qemuMigrationCookieFormat(mig, driver, vm, QEMU_MIGRATION_DESTINATION, cookieout, cookieoutlen, QEMU_MIGRATION_COOKIE_STATS) < 0) VIR_WARN("Unable to encode migration cookie");
//#0 qemuMigrationDstFinishFresh // (driver=<optimized out>, vm=<optimized out>, mig=<optimized out>, flags=<optimized out>, v3proto=<optimized out>, timeReceived=<optimized out>, doKill=<optimized out>, inPostCopy=<optimized out>) at ../src/qemu/qemu_migration.c:6715 //#1 qemuMigrationDstFinishActive // (cookie_flags=60, driver=0x56109f030930, dconn=0x7f93fc002f30, vm=<optimized out>, cookiein=0x7f941c041dc0 "0\t\003\237\020V", cookieinlen=32659, cookieout=0x7f942be99970, cookieoutlen=0x7f942be99964, flags=131073, retcode=0, v3proto=true, timeReceived=1780190289045, finishJob=<synthetic pointer>) at ../src/qemu/qemu_migration.c:6884 //#2 qemuMigrationDstFinish // (driver=driver@entry=0x56109f030930, dconn=dconn@entry=0x7f93fc002f30, vm=<optimized out>, cookiein=cookiein@entry=0x7f93fc001960 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>0cd0f6c9-2206-41ef-bb03-808873900a38</uuid>\n <hostname>src</hostname>\n <hostuuid>ba8b4bb8-c4bf-4da4-87bd-7f7a1ca07a7c</hostuuid>\n <statistics>\n"..., cookieinlen=cookieinlen@entry=1141, cookieout=cookieout@entry=0x7f942be99970, cookieoutlen=0x7f942be99964, flags=131073, retcode=0, v3proto=true) at ../src/qemu/qemu_migration.c:7010 //#3 0x00007f9428d524b7 in qemuDomainMigrateFinish3Params // (dconn=0x7f93fc002f30, params=0x7f93fc001de0, nparams=3, cookiein=0x7f93fc001960 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>0cd0f6c9-2206-41ef-bb03-808873900a38</uuid>\n <hostname>src</hostname>\n <hostuuid>ba8b4bb8-c4bf-4da4-87bd-7f7a1ca07a7c</hostuuid>\n <statistics>\n"..., cookieinlen=1141, cookieout=0x7f942be99970, cookieoutlen=0x7f942be99964, flags=131073, cancelled=0) at ../src/qemu/qemu_driver.c:11395 //#4 0x00007f942f4eb695 in virDomainMigrateFinish3Params // (dconn=dconn@entry=0x7f93fc002f30, params=0x7f93fc001de0, nparams=3, cookiein=0x7f93fc001960 "<qemu-migration>\n <name>migrate_guest</name>\n <uuid>0cd0f6c9-2206-41ef-bb03-808873900a38</uuid>\n <hostname>src</hostname>\n <hostuuid>ba8b4bb8-c4bf-4da4-87bd-7f7a1ca07a7c</hostuuid>\n <statistics>\n"..., cookieinlen=1141, cookieout=cookieout@entry=0x7f942be99970, cookieoutlen=0x7f942be99964, flags=131073, cancelled=0) at ../src/libvirt-domain.c:5485 //#5 0x000056109159788f in remoteDispatchDomainMigrateFinish3Params // (server=0x56109f01fbf0, msg=0x56109f01c820, client=<optimized out>, rerr=0x7f942be99a30, args=0x56109f023d30, ret=0x56109f01d390) at ../src/remote/remote_daemon_dispatch.c:5806 //#6 remoteDispatchDomainMigrateFinish3ParamsHelper (server=0x56109f01fbf0, client=<optimized out>, msg=0x56109f01c820, rerr=0x7f942be99a30, args=0x56109f023d30, ret=0x56109f01d390) // at src/remote/remote_daemon_dispatch_stubs.h:8656 //#7 0x00007f942f46888e in virNetServerProgramDispatchCall (prog=0x56109f020430, server=0x56109f01fbf0, client=0x7f9420000fd0, msg=0x56109f01c820) at ../src/rpc/virnetserverprogram.c:423 //#8 virNetServerProgramDispatch (prog=0x56109f020430, server=server@entry=0x56109f01fbf0, client=client@entry=0x7f9420000fd0, msg=msg@entry=0x56109f01c820) // at ../src/rpc/virnetserverprogram.c:299 //#9 0x00007f942f46de22 in virNetServerProcessMsg (srv=srv@entry=0x56109f01fbf0, client=0x7f9420000fd0, prog=<optimized out>, msg=0x56109f01c820) at ../src/rpc/virnetserver.c:135 //#10 0x00007f942f46e15d in virNetServerHandleJob (jobOpaque=0x7f941c09e460, opaque=0x56109f01fbf0) at ../src/rpc/virnetserver.c:155 //#11 0x00007f942f3b58bd in virThreadPoolWorker (opaque=<optimized out>) at ../src/util/virthreadpool.c:164 //#12 0x00007f942f3b4f44 in virThreadHelper (data=<optimized out>) at ../src/util/virthread.c:256 //#13 0x00007f942ed0eb7b in ??? () at /lib/x86_64-linux-gnu/libc.so.6 //#14 0x00007f942ed8c7f8 in ??? () at /lib/x86_64-linux-gnu/libc.so.6 staticint qemuMigrationDstFinishFresh(virQEMUDriver *driver, virDomainObj *vm, qemuMigrationCookie *mig, unsignedint flags, bool v3proto, unsignedlonglong timeReceived, bool *doKill, bool *inPostCopy) { ... /* We need to wait for QEMU to process all data sent by the source * before starting guest CPUs. */ if (qemuMigrationDstWaitForCompletion(vm, VIR_ASYNC_JOB_MIGRATION_IN, !!(flags & VIR_MIGRATE_POSTCOPY)) < 0) { /* There's not much we can do for v2 protocol since the * original domain on the source host is already gone. */ if (v3proto) return-1; }
/* Now that the state data was transferred we can refresh the actual state * of the devices */ if (qemuProcessRefreshState(driver, vm, VIR_ASYNC_JOB_MIGRATION_IN) < 0) { /* Similarly to the case above v2 protocol will not be able to recover * from this. Let's ignore this and perhaps stuff will not break. */ if (v3proto) return-1; }
... if (qemuProcessStartCPUs(driver, vm, runningReason, VIR_ASYNC_JOB_MIGRATION_IN) < 0) { if (virGetLastErrorCode() == VIR_ERR_OK) virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("resume operation failed")); /* * In v3 protocol, the source VM is still available to * restart during confirm() step, so we kill it off * now. * In v2 protocol, the source is dead, so we leave * target in paused state, in case admin can fix * things up. */ if (v3proto) return-1; } ... return0; }
/* Only after this point we can reset 'priv->beingDestroyed' so that * there's no point at which the VM could be considered as alive between * entering the destroy job and this point where the active "flag" is * cleared. */ vm->def->id = -1; priv->beingDestroyed = false;
/* No unlocking of @vm after this point until whole cleanup is done. */
/* Wake up anything waiting on domain condition */ virDomainObjBroadcast(vm);
if (priv->eventThread) g_object_unref(g_steal_pointer(&priv->eventThread));
if (g_atomic_int_dec_and_test(&driver->nactive) && driver->inhibitCallback) driver->inhibitCallback(false, driver->inhibitOpaque);
/* Stop autodestroy in case guest is restarted */ virCloseCallbacksDomainRemove(vm, NULL, qemuProcessAutoDestroy);
/* now that we know it's stopped call the hook if present */ if (virHookPresent(VIR_HOOK_DRIVER_QEMU)) { g_autofree char *xml = qemuDomainDefFormatXML(driver, NULL, vm->def, 0);
/* we can't stop the operation even if the script raised an error */ ignore_value(virHookCall(VIR_HOOK_DRIVER_QEMU, vm->def->name, VIR_HOOK_QEMU_OP_STOPPED, VIR_HOOK_SUBOP_END, NULL, xml, NULL)); }
/* Reset Security Labels unless caller don't want us to */ if (!(flags & VIR_QEMU_PROCESS_STOP_NO_RELABEL)) qemuSecurityRestoreAllLabel(driver, vm, !!(flags & VIR_QEMU_PROCESS_STOP_MIGRATED));
/* Clear out dynamically assigned labels */ for (i = 0; i < vm->def->nseclabels; i++) { if (vm->def->seclabels[i]->type == VIR_DOMAIN_SECLABEL_DYNAMIC) VIR_FREE(vm->def->seclabels[i]->label); VIR_FREE(vm->def->seclabels[i]->imagelabel); }
qemuHostdevReAttachDomainDevices(driver, vm->def); for (i = 0; i < def->nnets; i++) { virDomainNetDef *net = def->nets[i]; virDomainInterfaceDeleteDevice(def, net, QEMU_DOMAIN_NETWORK_PRIVATE(net)->created, cfg->stateDir); }
retry: if ((ret = virDomainCgroupRemoveCgroup(vm, priv->cgroup, priv->machineName)) < 0) { if (ret == -EBUSY && (retries++ < 5)) { g_usleep(200*1000); goto retry; } VIR_WARN("Failed to remove cgroup for %s", vm->def->name); }
/* Remove resctrl allocation after cgroups are cleaned up which makes it * kind of safer (although removing the allocation should work even with * pids in tasks file */ for (i = 0; i < vm->def->nresctrls; i++) { size_t j = 0;
/* Remove VNC and Spice ports from port reservation bitmap, but only if they were reserved by the driver (autoport=yes) */ for (i = 0; i < vm->def->ngraphics; ++i) { virDomainGraphicsDef *graphics = vm->def->graphics[i]; if (graphics->type == VIR_DOMAIN_GRAPHICS_TYPE_VNC) { if (graphics->data.vnc.portReserved) { virPortAllocatorRelease(graphics->data.vnc.port); graphics->data.vnc.portReserved = false; } if (graphics->data.vnc.websocketReserved) { virPortAllocatorRelease(graphics->data.vnc.websocket); graphics->data.vnc.websocketReserved = false; } if (graphics->data.vnc.websocketGenerated) { graphics->data.vnc.websocketGenerated = false; graphics->data.vnc.websocket = -1; } } if (graphics->type == VIR_DOMAIN_GRAPHICS_TYPE_SPICE) { if (graphics->data.spice.portReserved) { virPortAllocatorRelease(graphics->data.spice.port); graphics->data.spice.portReserved = false; }
if (graphics->data.spice.tlsPortReserved) { virPortAllocatorRelease(graphics->data.spice.tlsPort); graphics->data.spice.tlsPortReserved = false; } } }
for (i = 0; i < vm->ndeprecations; i++) g_free(vm->deprecations[i]); g_clear_pointer(&vm->deprecations, g_free); vm->ndeprecations = 0; vm->taint = 0; vm->pid = 0; virDomainObjSetState(vm, VIR_DOMAIN_SHUTOFF, reason); for (i = 0; i < vm->def->niothreadids; i++) vm->def->iothreadids[i]->thread_id = 0;
/* clean up a possible backup job */ if (priv->backup) qemuBackupJobTerminate(vm, VIR_DOMAIN_JOB_STATUS_CANCELED);
/* Do this explicitly after vm->pid is reset so that security drivers don't * try to enter the domain's namespace which is non-existent by now as qemu * is no longer running. */ if (!(flags & VIR_QEMU_PROCESS_STOP_NO_RELABEL)) { for (i = 0; i < def->ndisks; i++) { virDomainDiskDef *disk = def->disks[i];
if (disk->mirror) { if (qemuSecurityRestoreImageLabel(driver, vm, disk->mirror, false) < 0) VIR_WARN("Unable to restore security label on %s", disk->dst);
if (virStorageSourceChainHasNVMe(disk->mirror)) qemuHostdevReAttachOneNVMeDisk(driver, vm->def->name, disk->mirror); }
/* for now transient disks are forbidden with migration so they * can be handled here */ if (disk->transient && QEMU_DOMAIN_DISK_PRIVATE(disk)->transientOverlayCreated) { VIR_DEBUG("Removing transient overlay '%s' of disk '%s'", disk->src->path, disk->dst); if (qemuDomainStorageFileInit(driver, vm, disk->src, NULL) >= 0) { virStorageSourceUnlink(disk->src); virStorageSourceDeinit(disk->src); } } } }
/* clear all private data entries which are no longer needed */ qemuDomainObjPrivateDataClear(priv);
/* The "release" hook cleans up additional resources */ if (virHookPresent(VIR_HOOK_DRIVER_QEMU)) { g_autofree char *xml = qemuDomainDefFormatXML(driver, NULL, vm->def, 0);
/* we can't stop the operation even if the script raised an error */ virHookCall(VIR_HOOK_DRIVER_QEMU, vm->def->name, VIR_HOOK_QEMU_OP_RELEASE, VIR_HOOK_SUBOP_END, virDomainShutoffReasonTypeToString(reason), xml, NULL); }
virDomainObjRemoveTransientDef(vm);
endjob: if (asyncJob != VIR_ASYNC_JOB_NONE) virDomainObjEndJob(vm);
static virDomainPtr virDomainMigrateVersion3Full(virDomainPtr domain, virConnectPtr dconn, constchar *xmlin, constchar *dname, constchar *uri, unsignedlonglong bandwidth, virTypedParameterPtr params, int nparams, bool useParams, unsignedint flags) { /* If ddomain is NULL, then we were unable to start * the guest on the target, and must restart on the * source. There is a small chance that the ddomain * is NULL due to an RPC failure, in which case * ddomain could in fact be running on the dest. * The lock manager plugins should take care of * safety in this scenario. */ cancelled = ddomain == NULL ? 1 : 0; ... confirm: /* * If cancelled, then src VM will be restarted, else it will be killed. * Don't do this if migration failed on source and thus it was already * cancelled there. */ if (notify_source) { VIR_DEBUG("Confirm3 %p ret=%d domain=%p", domain->conn, ret, domain); VIR_FREE(cookiein); cookiein = g_steal_pointer(&cookieout); cookieinlen = cookieoutlen; cookieoutlen = 0; if (useParams) { ret = domain->conn->driver->domainMigrateConfirm3Params (domain, params, nparams, cookiein, cookieinlen, flags | protection, cancelled); } else { ret = domain->conn->driver->domainMigrateConfirm3 (domain, cookiein, cookieinlen, flags | protection, cancelled); } /* If Confirm3 returns -1, there's nothing more we can * do, but fortunately worst case is that there is a * domain left in 'paused' state on source. */ if (ret < 0) { VIR_WARN("Guest %s probably left in 'paused' state on source", domain->name); } } ... }
//#0 qemuMigrationSrcRestoreDomainState (driver=driver@entry=0x7fb90800f700, vm=vm@entry=0x7fb908503370) at ../src/qemu/qemu_migration.c:224 //#1 0x00007fb92a70efbd in qemuMigrationSrcConfirmPhase // (driver=driver@entry=0x7fb90800f700, vm=0x7fb908503370, cookiein=cookiein@entry=0x0, cookieinlen=cookieinlen@entry=0, flags=<optimized out>, // flags@entry=131329, retcode=retcode@entry=1) at ../src/qemu/qemu_migration.c:4127 //#2 0x00007fb92a70f15b in qemuMigrationSrcConfirm // (driver=0x7fb90800f700, vm=<optimized out>, cookiein=cookiein@entry=0x0, cookieinlen=cookieinlen@entry=0, flags=flags@entry=131329, cancelled=cancelled@entry=1) // at ../src/qemu/qemu_migration.c:4182 //#3 0x00007fb92a6d2236 in qemuDomainMigrateConfirm3Params (domain=0x7fb92c0013b0, params=<optimized out>, nparams=<optimized out>, cookiein=0x0, cookieinlen=0, flags=131329, cancelled=1) // at ../src/qemu/qemu_driver.c:11449 //#4 0x00007fb944e7ea30 in virDomainMigrateConfirm3Params (domain=domain@entry=0x7fb92c0013b0, params=0x7fb92c001400, nparams=2, cookiein=0x0, cookieinlen=0, flags=131329, cancelled=1) // at ../src/libvirt-domain.c:5537 //#5 0x00005590f61c0d3c in remoteDispatchDomainMigrateConfirm3Params (server=0x559111617bf0, msg=0x55911161d800, client=<optimized out>, rerr=0x7fb94282ea30, args=0x7fb92c000d80) // at ../src/remote/remote_daemon_dispatch.c:5863 //#6 remoteDispatchDomainMigrateConfirm3ParamsHelper (server=0x559111617bf0, client=<optimized out>, msg=0x55911161d800, rerr=0x7fb94282ea30, args=0x7fb92c000d80, ret=0x0) // at src/remote/remote_daemon_dispatch_stubs.h:8488 //#7 0x00007fb944dfb88e in virNetServerProgramDispatchCall (prog=0x559111618430, server=0x559111617bf0, client=0x55911160dfa0, msg=0x55911161d800) at ../src/rpc/virnetserverprogram.c:423 //#8 virNetServerProgramDispatch (prog=0x559111618430, server=server@entry=0x559111617bf0, client=client@entry=0x55911160dfa0, msg=msg@entry=0x55911161d800) // at ../src/rpc/virnetserverprogram.c:299 //#9 0x00007fb944e00e22 in virNetServerProcessMsg (srv=srv@entry=0x559111617bf0, client=0x55911160dfa0, prog=<optimized out>, msg=0x55911161d800) at ../src/rpc/virnetserver.c:135 //#10 0x00007fb944e0115d in virNetServerHandleJob (jobOpaque=0x5591115f7f60, opaque=0x559111617bf0) at ../src/rpc/virnetserver.c:155 //#11 0x00007fb944d488bd in virThreadPoolWorker (opaque=<optimized out>) at ../src/util/virthreadpool.c:164 //#12 0x00007fb944d47f44 in virThreadHelper (data=<optimized out>) at ../src/util/virthread.c:256 //#13 0x00007fb9446a1b7b in ??? () at /lib/x86_64-linux-gnu/libc.so.6 //#14 0x00007fb94471f7f8 in ??? () at /lib/x86_64-linux-gnu/libc.so.6 staticbool qemuMigrationSrcRestoreDomainState(virQEMUDriver *driver, virDomainObj *vm) { ... /* we got here through some sort of failure; start the domain again */ if (qemuProcessStartCPUs(driver, vm, VIR_DOMAIN_RUNNING_MIGRATION_CANCELED, VIR_ASYNC_JOB_MIGRATION_OUT) < 0) { /* Hm, we already know we are in error here. We don't want to * overwrite the previous error, though, so we just throw something * to the logs and hope for the best */ VIR_ERROR(_("Failed to resume guest %1$s after failure"), vm->def->name); if (virDomainObjGetState(vm, NULL) == VIR_DOMAIN_PAUSED) { virObjectEvent *event;